Like many in the research data management community, we have been closely following updates from the National Science Foundation (NSF) and National Institutes of Health (NIH) about changes to their data management and sharing plans (DMSPs, also known as DMPs).
For those not aware, both the NSF and NIH are moving away from free-form narrative document DMSPs towards more structured, standardized forms, which can then potentially be embedded directly into their proposal systems. NSF announced that their DMSPs will, starting on April 27th 2026, be completed as a form on Research.gov rather than uploaded as a separate document. NIH is also making a major change to their DMSP template starting May 25th 2026, also moving away from free-form text narrative to mostly Yes/No questions about data sharing, plus a list of expected outputs and their intended repositories and a space to explain any exceptions to data sharing.
These changes reflect a broader shift on how funders approach data management planning. Rather than narrative documents, DMSPs are becoming structured inputs that can be more easily reviewed, compared, and in some cases tracked over the course of a project.
Community Impact
We are happy to see a move towards structured, machine-actionable questions over free text and reducing burden on researchers applying for grants. However, these changes have the potential to disrupt the way data management and planning is done throughout the research lifecycle.
NSF’s new form may include the standard sections recommended in a DMSP, but the fact that it will only be accessible on Research.gov may make it harder for collaboration between researchers and data librarians to take place.
NIH’s form will still be uploaded as a document as far as we are aware, but limiting to mostly Yes/No questions may take away much of the planning that needs to happen before data is collected.
We understand both these updates are new and will undergo evaluation and feedback periods – we look forward to working with NSF and NIH to see how these new forms perform and if there are areas of improvement for the future.
The two main areas the DMP Tool team will be watching is cross-institutional communication and interoperability. In our experience, researchers and grants teams value personalized university guidance and the ability to collaborate with local data librarians and research IT teams to get feedback on their DMSPs. These new changes will require a shift in the way the community works but may also require further refinement from the agencies.
We also hope to see more investment in interoperability in the future. Locking the DMSP information into a closed system without an API risks creating a new silo of important research information that will make it harder for other researchers to find and track data outputs from funded research. We hope that the agencies look for new ways for researchers to engage with their platforms that enable these types of interoperability and connectivity.
Adjusting to new workflows
While the DMP tool team continues to understand the implications of these new workflows, we are also committed to meeting the needs of our communities. Many have reached out to ask specific questions around how we will adjust the tool to work with NSF and NIH’s new approaches.
For NSF, as soon as the final version of the Research.gov form is available, we will implement a copy of it into the tool. People who complete their DMSP for NSF in the DMP Tool will still be able to use its collaboration and guidance for help filling it out, though at the end they will likely need to copy/paste the information into the Research.gov form rather than export as a PDF. Regardless, the key features that support collaboration and communication will still be available for institutions to use in NSF proposal consultations.
For NIH, we have already started work implementing the new form based on the preview provided. The questions are already entered, and we’re working with members of our DMP Tool Editorial Board to add appropriate guidance, recommendations, and relevant policies to the elements. As soon as the NIH form is finalized and we have that entered, we will publish it on the DMP Tool so researchers can start to use it for upcoming submissions, and organizations can start adding customizations and extra guidance if they wish.
Stay updated on the latest! We will message our status and next steps on this blog, our LinkedIn account, and direct emails to all member organization contacts.
Implications on our ongoing platform development
As we described above, in the immediate future, we will continue to support creating DMSPs in the tool for NSF, NIH, and many other US and international funders however they structure their templates. In parallel, our rebuild work continues on. We will be taking these new announcements as opportunity to reflect and adjust our priorities and timelines. We think that many of the new functionalities coming in the new tool fit well with this evolving landscape. For example, the new tool will support creating a Project that can house multiple related plans and allow uploads of plans created elsewhere. This could allow, for example, people to upload a copy of the plan they submitted to NSF to the tool, and house related plans within one research project. This allows for support of Data Security Plans, Software Management Plans, and other documents that many universities and field stations now require.
In the long term, we’re committed to evolving the DMP Tool to meet the needs of the community, even as those needs change. We will continue to have open conversations about how to properly prioritize and adapt our current efforts for the changes we see coming on the horizon.
Our core commitment is to serve and promote best practices in data management planning, and that goes beyond the document itself. We know that our community’s strengths are in the customized guidance, collaboration, and resources that we all bring together from researchers, funders, and universities into one place, and we think that is more valuable than ever. We will keep you all posted as we address the evolving landscape together!
Welcome to the second post of UC3’s New Year blog post series, where different services of UC3 take a look at the coming year. If you haven’t already read it, check out the first one on digital preservation.
Over in the world of Data Management Planning, we’ve got a lot of exciting work this year to share!
Our main project continues to be working on the rebuild of the DMP Tool. While we initially hoped to have it ready early this year, we’re now targeting the summer of 2026. This gives us more time to make sure it’s at a high level of quality, and also releases it at a time that will hopefully be less disruptive to people who teach classes using the DMP Tool. There’s a chance it will take longer than the summer though – we’re focused on quality over speed.
We’ve done 3 rounds of user testing so far on the site, and each time has given us a lot of valuable information. We’ve gotten a lot of positive feedback about new features we will be offering, such as alias email addresses, adding collaborators to templates, a revamped API, and much more. Other changes, though, have caused some confusion for people used to the current tool, and through testing we have found opportunities to improve the workflow and usability of the new site. These are the types of changes that mean the rebuild will take longer than initially planned to complete, but we think are worth the time to get right.
To keep updates about the rebuild in one place, we have a Rebuild Hub page on our blog. We’ll keep this page up to date with the latest information about the release date, FAQ, status updates, and more. We plan to make posts leading up to the new release showing the major changes and giving guidance to make the transition as seamless as possible. If you’d like to help with testing at any point, please sign up for our user panel to get invitations to future feedback sessions.
As we’ve said before, we’re limiting updates to the current tool so we can focus our limited resources on the rebuild; but of course we also want to keep the tool live and helpful during the transition. We’re fixing any major issues that come up, such as keeping it up to date with new ROR API and schema, and addressing user tickets as quickly as possible. We are trying to keep funder templates up to date as well, but the frequency of new information and potential changes has made it difficult to perfectly capture all updates to federal guidelines. We want to make sure we have the most relevant information possible on the tool without changing templates too often (as that can lose organization guidance), so we’ve been collecting updates from our Editorial Board members for a template release in the near future. If you see any instances where a template in our tool does not match a funder template, please reach to us by email so we can get it corrected.
Get Involved with API Integrations
With our rebuild is coming a complete revamped API to take advantage of our new machine-actionable functionality. We’re currently looking for partners that would like early access to our new API in order to develop new integrations for our rebuild. Our goal is that the new API can do anything the user interface can do, which means the sky (or more relevant, the cloud) is the limit for possible tools. If you’ve been wanting to connect to our API for some sort of automation that our current API did not offer the capability for, we’d love to hear from you. You can hear more about past pilot integrations and how to work with our API at this recording of our webinar from the Machine-Actional Plans pilot project. We’ll be following the common API standard being developed with the Research Data Alliance, meaning many integrations with our tool should work for other DMP service providers as well. If you have an idea for an integration you’d like to build on our new API, please reach out to dmptool@ucop.edu!
Matching to Published Research Outputs
We’ve talked before about a major project to use machine learning models to help match DMPs to their eventual research outputs, like datasets and software publications, to help make data from published DMPs easier to find and re-use. This work has continued and we plan to release it with the rebuilt DMP Tool. Since our last update, we’ve made some significant steps towards this goal, including:
Moving the infrastructure onto our own servers to prepare for integration into the DMP Tool
Adding new sources of data, such as grant award pages that list published outputs
Getting the normalized corpus into OpenSearch to aid us in the matching process
Expanding our ground truth dataset of true matches and non-matches to help test our matching algorithm
Utilizing a Learning to Rank model that will improve over time as it learns from accepted and rejected matches
Building out the user interface for how users will see potential matches and accept or reject them
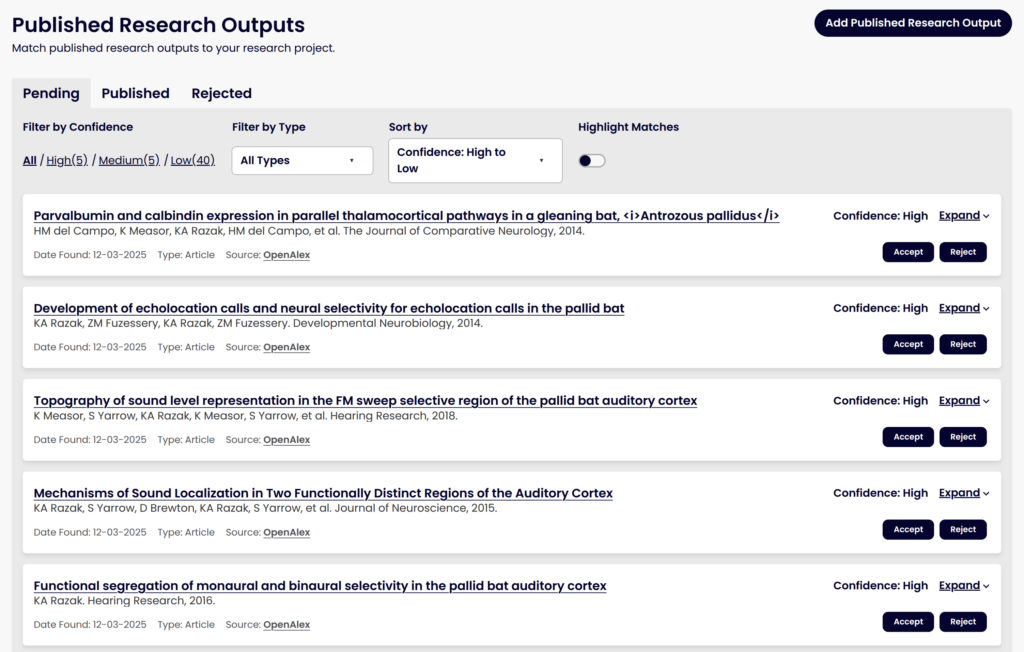
New user interface showing a list of published outputs that have been matched to a DMP in our rebuilt DMP Tool. Interface is subject to change before release.
Improvements we plan to work on over 2026 include:
Adding in related outputs based on accepted outputs (i.e., finding matches to any Accepted works in addition to matching against the DMP itself)
Looking at options to improve the matching algorithm, such as vector search with an embedding model
Working with the COMET team on tooling that can extract award IDs from published outputs, which will improve the quality of matching to DMPs that include an award ID
We’re excited for people to get to use this tool with the rebuild and start accepting and rejecting potential matches so we can learn from this and improve the matching algorithm further over time. People will also be able to manually add DOIs as research outputs, like they can on the current tool, which will also help train the model over time on what we missed as potential matches. This will be available for all DMPs that have been published, i.e., registered for a DMP ID. Accepted works will be added to the metadata for the plan as related identifiers.
DMP Chef
Another exciting area we’re exploring is the use of generative AI to assist in writing Data Management Plans. We’ve partnered with the FAIR Data Innovations Hub to work on the DMP Chef, a project to explore using large language models (LLMs) to draft DMPs. Our goal is not to take away the key decisions in data management planning from a researcher, but instead to simplify the process as much as possible by asking a few critical questions, combining that responses with funder requirements that need to be met, and using those to produce a draft of a DMP for their review and edits.
We have promising early results, with both automated statistics and human evaluations showing the LLM-drafted DMPs can be comprehensive, accurate, and follow best practices. Commercial models are performing better than the open-source models, but since we want to remain open-source, we’re looking at ways to improve the open-source models through additional retrieval augmented generation and other options. And we’ll be testing carefully how accurate and helpful the output is, as well as looking at ways to help ensure researchers read and edit the plan as needed, rather than just accept the output right away.
DMP Source
Overall Satisfaction rating (1-5)
Average Error Count per DMP
Accuracy in guessing LLM vs Human
Human
3.1
7.2
65%
LLMs (combined)
3.4
4.9
43%
Llama 3.3
2.6
7.5
70%
GPT-4.1
4.2
2.3
15%
Results presented at the Research Data Alliance 2025 plenary, showing GPT-4.1 generated DMPs with higher satisfaction ratings and fewer errors reported than human-written exemplar DMPs from NIH. N = 20 participants rating a DMP from each source, for a total of 60 DMP ratings
Over the course of 2026, we plan to keep testing and improving this model, starting with NIH and NSF plans. The ultimate goal is a general use model that can be used within the DMP Tool for any funder to get a first draft of either a whole DMP or specific sections a researcher is struggling with. We have a working prototype tool for DMP generation we will use for testing purposes, with integration into the DMP Tool planned for further out. If you’d like to be part of testing out this new tool, please sign up for our user panel.
Thanks for reading about our major initiatives for the year! Keep an eye out on this space for the next post in our series, about our 2026 plans for persistent identifiers.
The Machine Actionable Plans (MAP) Pilot project is currently in its final phase, providing institutions with resources to enable them to explore the potential uses of machine-actionable data management plans (maDMPs). The project webpage includes newly released resources including the final report, case studies, and key recommendations, as well as links to recorded webinars and other materials.
Pilot Overview
The pilot was funded by the Institute of Museum and Library Services (IMLS LG-254861-OLS-23) and grew out of a partnership between the California Digital Library and the Association of Research Libraries. Designed to address the urgent needs of academic libraries to meet increasing requirements for sharing research data, it explored the integration of maDMPs with existing research and IT systems.
The pilot, discussed in pastblogposts, worked directly with several institutions, providing the opportunity to take the infrastructure built by the DMP Tool and implement machine-actionable approaches in alignment with their organization’s goals. Each institution designed its own project with consideration given to local data management challenges and opportunities. Some focused on technical developments using API integrations, including automation and prototype tool build, while others prioritized collaboration and relationship-building across departments in support of research data management. Partners found value in not only progressing pilots at their own institutions, but sharing learnings and outcomes across institutions, deepening insight into common challenges and opportunities, as well as expanding collaborative relationships.
CDL’s Maria Praetzellis notes:
At California Digital Library (CDL), we collaborate with UC campus Libraries and other partners to amplify the academy’s capacity for innovation, knowledge creation and research breakthroughs. The MAP Pilot project is an excellent example of this being realized. We’ve seen so many examples of collaboration, innovation, and expertise resulting in impressive tangible solutions for institutions in the face of increasing challenges and opportunities. Even in cases where institutions were unable to advance a solution within the span of the pilot, they were able to explore new paths to doing so in the future, all while building meaningful connections across campus and obtaining clarity on paths forward to advance institutional strategic priorities. This work has been strongly representative of the kinds of innovation CDL strives to facilitate.
Another key aim of the MAP pilot was to gather feedback to inform improvements to the DMP Tool. This feedback focused on workflows for uploading existing plans, automatic linking of plans to related outputs, enhancing API integrations, and improving the overall user experience. The input from the pilot institutions was crucial for identifying gaps and shaping the design of new DMP Tool features, which will be incorporated in the upcoming DMP Tool Rebuild. CDL’s Becky Grady comments:
Receiving feedback on the DMP Tool user interface and API during the course of the pilot was incredibly useful for its development. Our pilot partners provided important perspectives on their experience using the tool and the API, which informed key developments in our user interface redesign. The DMP Tool team feels more confident in our direction for continued development, now with greater clarity on the priorities to provide the biggest benefits for researchers and institutions.
Several new resources have been created for institutions, informed by key learnings from the pilot.
An overview report for the pilot has been prepared to provide information around the project’s background, summary of pilot activities and DMP Tool development, pilot observations, and key recommendations for institutions.
Pilot partners, including Arizona State University, Northwestern University, Pennsylvania State University, the University of California, Riverside, and the University of Colorado Boulder, share their pilot activities, learnings, and recommendations in a series of short case studies.
A collection of short recommendation guides has been prepared for institutional stakeholder groups to support those exploring maDMPs. Guides are available for researchers, librarians, IT & Information Security departments, and grant offices.
Several partner institutions are also preparing additional reports with more detail to be made available to the wider community. These will be listed on the MAP Pilot Project webpage as they become available.
The MAP Pilot team hopes that institutions and DMP Tool administrators will find these resources useful in engaging with colleagues at their institution to explore the deep benefits that maDMPs can yield. They would like to thank all of the pilot institutions for their participation, collaboration, and generosity with their time in sharing their learnings with the community.
Want to learn about how technological advancements in data management plans can benefit research at your university? Have you heard the term “machine-actionable” a lot but aren’t sure what it is or why it’s important? Are you looking for strategies to reduce burden on researchers and administrators in working on data management plans?
Join our free webinar series to learn from several US institutions that explored and piloted machine-actionable approaches to data management plans (DMPs).
Funded by the Institute of Museum and Library Services (award LG-254861-OLS-23), and led jointly by the California Digital Library (CDL) and the Association of Research Libraries (ARL), the Machine Actionable Plans (MAP) Pilot initiative enabled institutions to test and pilot data management plans that are machine-actionable and facilitate communication with other university research and IT systems. Each institution developed its own projects in alignment with their institutional mission, and with their specific challenges and opportunities taken into consideration. The DMP Tool team also worked with pilot partners to test features and advance technical developments to improve usability, best practice adoption, compliance, and efficiency.
In this series of webinars, we invite librarians, administrators, data managers, IT & security staff to find out more about the motivations of these institutions to explore machine-actionable DMP integrations: what they did, how they did it, and what they learned. For those interested in more technical aspects of integrations, some webinars will also provide detail on the API of the DMP Tool, along with more detailed implementation instructions and advice.
Webinar 1: Streamlining Research Support: Lessons from maDMP Pilots
Tuesday, May 6, Noon EDT / 9:00 a.m. PDT Duration: 1 hour, with an optional additional 15 minutes for Q & A
This webinar is for those looking to improve the efficiency, collaboration, and coordination of research support within their institutions. Learn from several institutions about their explorations of maDMP integrations to facilitate automated notifications for coordination across campus, and about how they used the pilot more broadly to facilitate discovery and collaboration within their institutions. This webinar will provide an overview of each institution’s activity, rather than detailed instructions about integrations.
Presenters include: Katherine E. Koziar, Briana Wham, Matt Carson, Andrew Johnson
Webinar 2: Creative Approaches for Seamless and Efficient Resource Allocation
Tuesday, May 20, Noon EDT / 9:00 a.m. PDT
Duration: 1 hour, with an optional additional 15 minutes for Q & A
Don’t miss this webinar if you’re interested in new ways to enable efficient resource allocation. Institutions will share their experiences in leveraging maDMPs to develop integrations for automation systems that enable such allocations. This webinar will provide an overview of each institution’s activity, rather than detailed technical instructions about integrations.
Presenters include: Katherine E. Koziar, Andrew Johnson
Webinar 3: Five Technological Advancements in DMPs to Benefit Your Organization
Tuesday, June 3, Noon EDT / 9:00 a.m. PDT
Duration: 1 hour, with an optional additional 15 minutes for Q & A
If you’re interested in emerging technologies within the pilot project and the DMP Tool and how they can help your institution expedite research sharing, compliance, and operational efficiency, this webinar will provide a strong introduction. We’ll also hear from pilot partners about promising AI developments related to reviewing DMPs, and will hear more detail on technical advancements coming to the DMP Tool based on feedback from the pilot.
WEBINAR 4: How to Implement Machine-Actionable DMPs at your Institution
Tuesday, June 17, Noon EDT / 9:00 a.m. PDT
Duration: 1 hour, with an optional additional 15 minutes for Q & A
If you want to find out more about specific integrations and how to implement maDMPs, this webinar is for you. Hear from the DMP Tool team about the API, common challenges and how to overcome them, and actionable recommendations for campus buy-in.
We’re participating in a new group formed to develop a common API standard for DMP service providers
The goal is to make it easy for anyone wanting to build integrations with maDMPs to have it work for any DMP service provider
The group had its first kick-off meeting to make initial outlines, with work continuing over the next few months
We plan to support the new API (as well as all existing functionality and integrations) in our new rebuilt DMP Tool application
DMP Tool and the Research Data Alliance
Our work at DMP Tool has been shaped from the ground up through collaborations at the Research Data Alliance (RDA). From the earliest conversations about machine-actionable Data Management Plans (maDMPs) to the creation of the DMP common standard and the DMP ID, the RDA has served as the convening space where we’ve found shared purpose, co-developed solutions, and built lasting partnerships with peers across the globe. That same spirit is captured in the Salzburg Manifesto on Active DMPs, which outlines a vision for DMPs as living, integrated components of the research lifecycle. That vision continues today, as we are helping launch a new initiative at RDA to update a common API standard for DMP service providers. This effort will help ensure our systems can connect more seamlessly and serve the broader research ecosystem more effectively. This post gives some context on why this new effort is needed, what we’ve done so far for it, and what we have coming next.
DMP Tool implementation of the RDA common standard
The DMP Tool team were early advocates of maDMPs and saw the potential value of capturing structured information during the creation of a DMP. The goal is to use as many persistent identifiers (PIDs) as possible to help facilitate integrations with external systems. To gather this data, we introduced new fields into the DMP Tool to capture detailed information about project contributors (ORCIDs, RORs, and CRediT roles) as well as what repositories (re3data), metadata standards (RDA metadata standards) and licenses (SPDX) would be used when creating a project’s research outputs. These new data points are captured alongside the traditional DMP narrative. We also started allowing researchers to publish their DMPs. This process generates a DMP ID, a DOI customized to capture and deliver DMP-focused metadata. This approach allows the DMP to be discoverable in knowledge graphs like DataCite Commons. Once the DOI is registered, the DMP Tool provides a landing page for the DOI.
One of the main points of collecting all of this structured metadata is to facilitate integrations with other systems. To make that possible, we introduced a new version of the API that outputs the DMP metadata in the common standard developed with RDA. Our first integration was with the RSpace electronic lab notebook system. When a researcher is working in RSpace, they are able to connect RSpace with the DMP Tool to fetch their DMPs in PDF format and store the document alongside their other research outputs. Once connected, RSpace is able to send the DMP Tool the DOIs of any research outputs that the researcher deposits in repositories like Dataverse or Zenodo. These DOIs are then available as part of the DMPs structured metadata.
Moving the Standard Forward
The original RDA DMP common standard was released 3 years ago. Since that time, systems like the DMP Tool have found areas where we need to deviate from the base standard. This is a normal process when any standard is developed and first put into use. We have discovered key fields that should be added to the standard (e.g., contributor affiliation information) and areas that don’t really make sense to capture within the DMP itself (e.g., the PID systems a particular repository supports).
Other DMP systems have also been implementing the common standard and making it available via API calls, but this was done without conformity as to how an external system can access those APIs. This results in systems like RSpace needing to develop and maintain separate integrations for each tool. Over time, this extra work leads to fewer integrations between systems, making each more siloed.
RDA is made up of Interest Groups and Working Groups where members across the world join together to work on a common topic, making guidelines, best practices, tools, standards, and other resources for the wider community. To tackle this use case and address shared issues, our RDA group decided to release a new version of the common standard, v1.2, and forming a new working group to develop API standards that each tool should support. Members of the DMP community gathered together at the end of March to discuss both topics. The DMP systems represented at the meeting included Argos, DAMAP, Data Stewardship Wizard, DMPonline, DMP OPIDoR, DMP Tool, DMPTuuli, and ROHub.
Our DMP Tool team attended the meeting to make sure that the needs of our funders, researchers and institutions were properly represented. The meeting was split into two parts:
Common Standard revisions: In the morning, the group reviewed issues and feature requests submitted to the DMP Common Standard GitHub repository over the past three years. These were synthesized into major themes for discussion, resulting in a set of proposed non-breaking changes for a v1.2 release. More complex revisions were deferred for a future v2. Those interested can explore the open issues here.
Drafting the API specification: In the afternoon, the group reviewed user stories from current and planned integrations to identify common needs. This discussion led to the initial outline of a shared set of API endpoints that each DMP service should support. Work on refining this draft will continue in the coming months.
Meeting attendees, representing a variety of DMP service providers, worked together on the common standard
Next steps
The original common metadata standard working group plans to incorporate the proposed non-breaking changes this summer as release v1.2. We have also committed to keep the conversation going about future enhancements as we work towards v2.
Meanwhile, the new RDA working group also hopes to release an official API specification this summer. The individual tools would then be tasked with ensuring that their systems support the new API endpoints. For our part, the DMP Tool will ensure that our new website supports this API standard when it launches, as well as additional endpoints specific to our application. The goal is that integrator services like RSpace will then be able to connect more easily with any DMP service, making connections across the research system more robust.
Anyone can review the new DMP common API for maDMP working group proposed work statement. We would value your input, and if you’re interested in joining the group and contributing to the API specification, you can join RDA (its free!) and join our Working Group.
We’re gearing up for a big year over at the DMP Tool! Thousands of researchers and universities across the world use the DMP Tool to create data management plans (DMPs) and keep up with funder requirements and best practices. As we kick off 2025, we wanted to share some of our major focus areas to improve the application, introduce powerful new capabilities, and engage with the wider community. We always want to be responsive to evolving community needs and policies, so these plans could change if needed.
New DMP Tool Application
Our primary goal for the year is to launch the rebuild of the DMP Tool application. You can read more detail about this work in this blog post, but it will include the current functionality of the tool plus much more, still in a free, easy to use website. The plan is still to release this by the end of 2025, likely in the later months (no exact date yet). We’re making good progress towards a usable prototype of core functionality, like creating an account and making a template with basic question types.
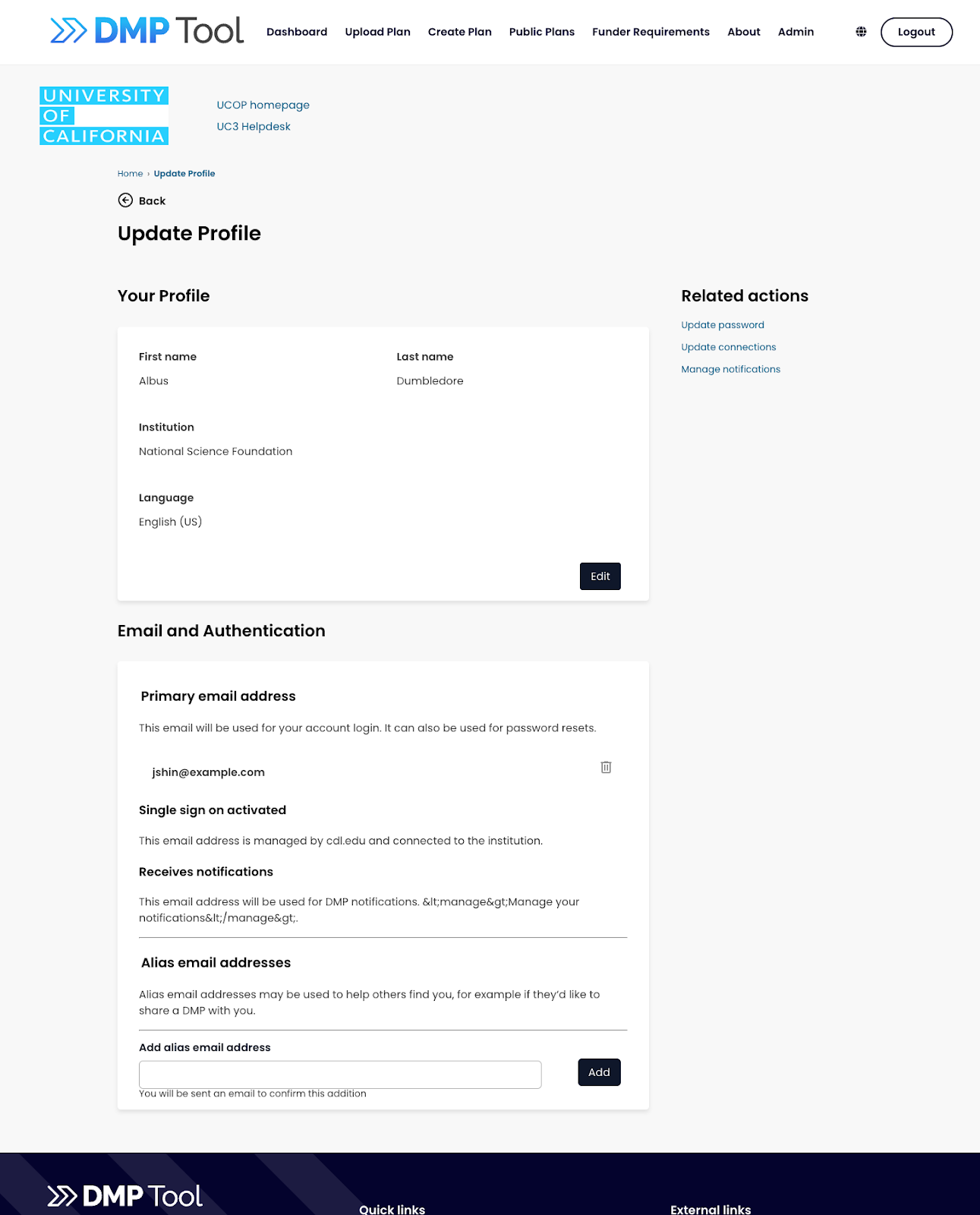
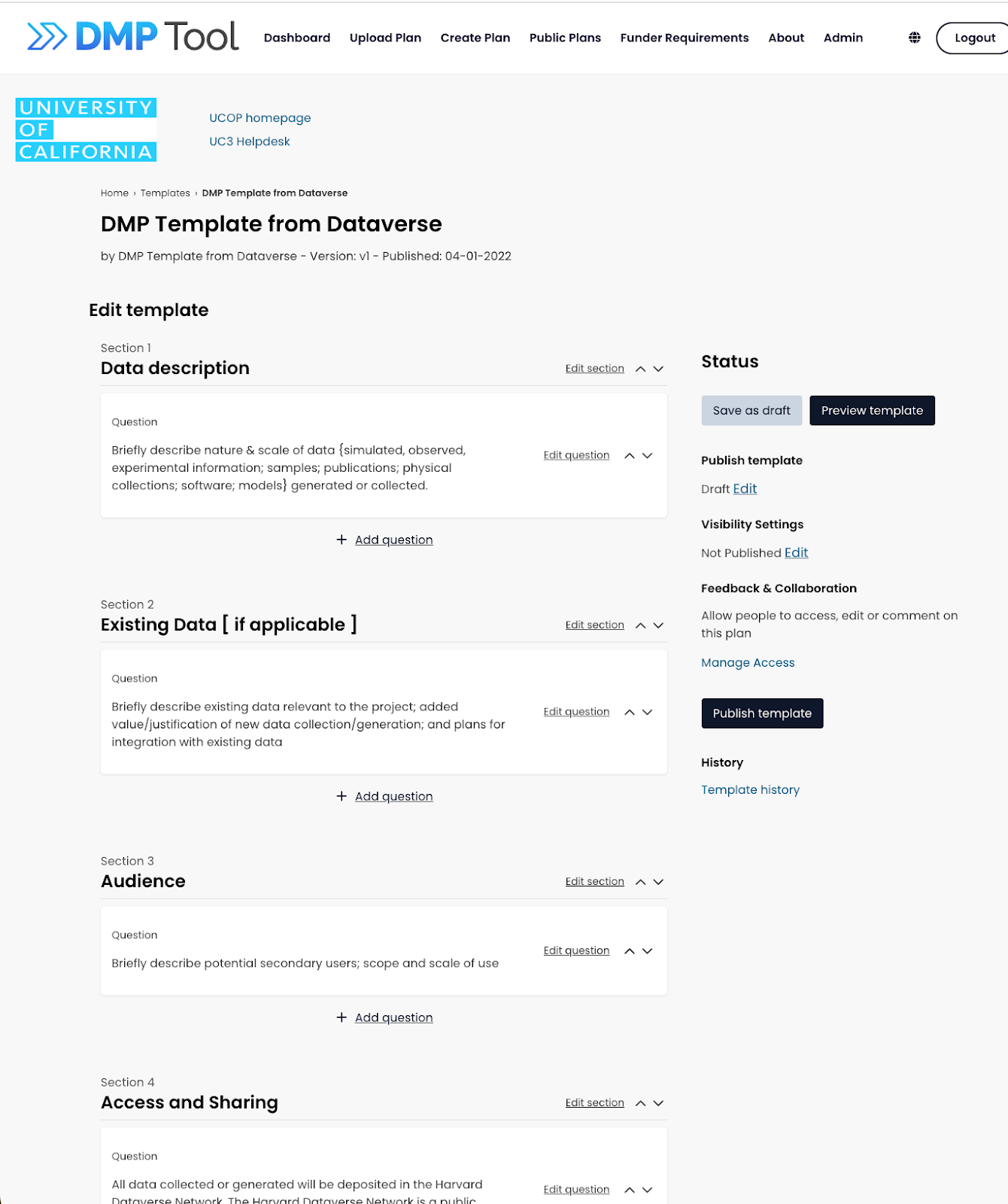
In-development screenshot of account profile page in the new tool. Page is not final and is subject to change.In-development screenshot of editing a template in the new tool. Page is not final and is subject to change.
Another common request is to offer more functionality within our API. For example, people can already read registered DMPs through the API, but many librarians want to be able to access draft DMPs to integrate a feedback flow on their own university systems. As part of our rebuild, we are moving to a system that is going to use the same API on the website as the one available to external partners (GraphQL for those interested). This will allow almost any functionality on the website to be available through the API. This should be released at the same time as the new tool, with documentation and training to come. Get your integration ideas ready!
Finally, we are continuing to work on our related works matching, tracking down published outputs and connecting them to a registered DMP. This is part of an overall effort to make DMPs more valuable throughout the lifecycle of a project, not just at the grant submission stage, and to reduce burden on researchers, librarians, and funders to connect information within research projects. It’s too early to tell when this will be released publicly on the website, but likely will come some time after the rebuild launch.
AI Exploration
While most of our focus will be on the above projects, we are in the early stages of exploring topics for future development of the DMP Tool. One big area is in the use of generative AI to assist in reviewing or writing data management plans. We’ve heard interest from both researchers and librarians in using AI to help construct plans. People sometimes write their DMP the night before a grant is due and request feedback without enough time for librarians to provide it. AI could help review these plans, if trained on relevant policy, to give immediate feedback when there’s not enough time for human review.
We’re also interested in exploring the possibility of an AI assistant to help write a DMP. We know many people are more comfortable answering a series of multiple choice questions than they are in crafting a narrative, and it’s possible we could help turn that structured data into the narrative format that funders require, making it easier for researchers to write a plan and keeping the structured data for machine actionability. Another option is an AI chatbot within the tool that can help provide our best practice guidance in a more interactive format. It will be important for us to balance taking some of the writing burden off of researchers while making sure that they are still the one responsible for the content within it.
These ideas are in early phases – it’s something we’ll be exploring with some external partners but likely not releasing to the public this year – however we’re excited about their potential to make best practice DMPs easier to create.
Community Engagement
While we’ll sometimes be heads down working on these big projects, we also want to make sure we’re communicating to and participating in the wider community more than ever. As we get towards a workable prototype of the new tool, we’ll be running more user research sessions. The initial sessions, reviewed here, offered a lot of valuable insight that shaped the current designs, and we know once people get their hands on the new tool they’ll have more feedback. If you haven’t already, sign up here to be on the list for future invites.
We also want to be more transparent with the community about our operations and goals. We’ve started putting together documents within our team about our Mission and Vision for the DMP Tool, which we’ll be sharing with everyone shortly. Over 2025, we want to continue to work on artifacts like those we can share regularly so that you all know what our priorities are. One goal is to create a living will, recommended by the Principles of Open Scholarly Infrastructure, outlining how we’d handle the potential winddown of CDL managing the DMP Tool. This is a sensitive area because we have no plans to wind down the tool, and don’t want to give the impression that its going away! But it’s important for trust and transparency for us to have a plan in place if things change, as we know people care about the tool and their data within it.
Finally, we’ll be wrapping up our pilot project with ARL this year, where we had 10 institutions pilot implementation of machine-actionable DMPs at their university. We’ve seen prototypes and mockups for integrations related to resource allocation, interdepartmental communication, security policies, AI-review, and so much more. We’ve brought on Clare Dean to help us create resources and toolkits, disseminate the findings, and host a series of webinars about what we’ve learned to help others implement at their own universities. We’ll be presenting talks on the DMP Tool at IDCC25 in February, RDAP in March, and we plan to submit for other conferences throughout the year, including IDW/RDA in October, to share what we’ve learned with others. We hope to continue working with DMP-related groups in RDA to ensure our work is compatible with others in the space, and we’re following best practices for API development.
We hope you’re as excited for these projects as we are! We’re a small team but we work with many amazing partners that help us achieve ambitious goals. Keep an eye on this space for more to come.
We’re making progress on our plan to match DMPs to associated research outputs.
We’ve brought in partners from COKI who have applied machine-learning tools to match based on the content of a DMP, not just structured metadata.
We’re getting feedback from our maDMSP pilot project to learn from our first pass.
In our new rebuilt tool, we plan to have an automated system to show researchers potential connected research outputs to add to the DMP record.
Connecting Related Works
Have you ever looked at an older Data Management Plan (DMP) and wondered where you could find resulting datasets it mentioned would be shared? Even if you don’t sit around reading DMPs for fun like we do, you can imagine how useful it would be to have a way to track and find published research outputs from from a grant proposal or research protocol.
To make this kind of discovery easier, we aim to make DMPs more than just static documents used only in grant submissions. By using the rich information already available in a DMP, we can create dynamic connections between the planned research outputs — such as datasets, software, preprints, and traditional papers — and their eventual appearance in repositories, citation indexes, or other platforms.
Rather than linking each output manually to their DMP, we’re using the new structure of our machine actionable data management and sharing plans (maDMSPs) from our rebuild to help automate these connections as much as possible. By scanning relevant repositories and matching the metadata to information in published DMPs, we can find potential connections that researchers or librarians just have to confirm or reject, without adding the information themselves. This keeps them in control and helps ensure connections are accurate, while reducing the burden of how much information they have to enter.
Image from an early version of this in the DMP Tool showing a list of citations for potential marches with buttons to Review and a status column showing them as Approved or Pending
This helps support the FAIR principles, particularly making the data outputs more findable, and helps transform DMPs into useful, living documents that provide a map to a research project’s outputs throughout the research lifecycle.
Funders, librarians, grant administrators, research offices, and other researchers will all benefit from a tracking system like this being available. And thanks to a grant from the Chan Zuckerberg Initiative (CZI), we were able to start developing and improving the technology to start searching across the scholarly ecosystem and matching to DMPs.
The Matching Process
We started with DataCite, matching based on titles, contributors (names and ORCIDs), affiliations, and funders (names, RORs and Crossref funder ids). Turns out, when you have a lot of prolific researchers, they can have many different projects going on in the same topic area, so that’s not always enough information to to find the dataset from this particular project. We don’t want to just find any datasets or papers that any monkey-researcher has published about monkeys, we want to find the ones that are from this particular grant about monkey behavior.
To help expand the datasets and other outputs we could find, we partnered with the Curtin Open Knowledge Initiative (COKI) to ingest information from OpenAlex and Crossref, and we’re working on including additional sources like the Data Citation Corpus from Make Data Count. COKI’s developers are also applying machine-learning, using embeddings generated by large language models and vector similarity search to compare the text from the title and abstract of a DMP to those descriptive fields within the datasets, rather than just the metadata for authors and funders. That will help us match if, say, the DMP mentions “monkeys” but the dataset uses the work “simiiformes.”
To confirm the matches, we used pilot maDMSPs from institutions that are part of our projects with our partners at the Association of Research Libraries, funded by the Institute of Museum and Library Sciences and the National Science Foundation. This process recently yielded a list of 1,525 potential matches to registered DMPs from the pilot institutions. We asked members of the pilot cohort to evaluate the accuracy of these matches, providing us with a set of training data we can use to test and refine our models. For now we provided the potential matches in a Google Sheet, but in the future with our rebuild we plan to integrate this flow directly in the tool.
Screenshot from one university’s Google Sheet for matching DMP-IDs to research output DOIs, showing some marked as Yes, No, and Unsure for if its a match
Initial Findings
It will take some time for the partners to finish judging all the matches, but so far about half of the potential related works were confirmed as related to the DMP. This means we’ve got a good start and can use the ones that didn’t match to train our model better. We’ll use those false positives, as well as false negatives gathered from partners, to refine our matching and get better over time. Since we’re asking the researchers to approve the matches, we’re not too worried about false matches, but we do want to find as many as possible.
This process is still early, but here are some of our initial learnings:
Data normalization is an important and often challenging step within the matching process. In order to match DMPs to different datasets, we need to make sure that each field is represented consistently. Even a structured identifier like a DOI can be represented with many different formats across and within the sources we’re searching. For example, sometimes they might include the full URL, sometimes just the identifier, and some are cut off and therefore have an incorrect ID that needs to be corrected in order to resolve. That’s just one small example, but there are many more that make the cleanup difficult, including normalization of affiliation, funder, grant and researcher identifiers across and within the datasets. Without the ability to properly parse the information, even a seemingly comprehensive source of data may not be useful for finding matches.
Articles are still much easier to find and match than datasets. This is not surprising, given the more robust metadata associated with DOIs for articles that make them easier to find. Data deposited into repositories often does not have the same level of metadata available to match, if a DOI and associated metadata are even available at all. We’re hoping we can use those articles, which may mention datasets, to find more matches in our next pass.
There is not likely to be a magic solution that gets us to completely automate the process of matching a research output to a DMP without changes in our scholarly infrastructure. Researchers conduct a lot of research in the same topic area, so it’s difficult to know for sure if a paper or dataset came from a DMP, unless they specifically include these references. There are ways to improve this, such as using DOIs and their metadata to create bi-directional links between funding and their outputs (as opposed to one-directional use of grant identifiers), including in data repositories. DataCite and Crossref are both actively working to build a community around these practices, but many challenges still remain. Because of this, we plan to have the researcher confirm matches before they are added to a record, rather than attempt to add them automatically.
Next Steps
We’re continuing to spend most of our development work on our site rebuild, which is why we’re grateful for our funding from CZI and our partnership with COKI to improve our matching. Our next step is including information from the Make Data Count Data Citation Corpus, as well as following up on the initial matches once pilot partners finish their determinations.
We hope to have this Related Works flow added to our rebuilt dmptool.org website in the future. The mockup is below (where we show researchers that we have found potential related works on a DMP, and would then ask them to confirm if it’s related so it can be added to the metadata for the DMP-ID and become part of the scholarly record). We’ll want to balance confidence and breadth, finding an appropriate sensitivity so that we don’t miss potential matches but also don’t spam people with too many unrelated works.
Mockup of a project block in the new DMP Tool which a red pip and test saying “Related works found”
If you have feedback on how you would want this process to work, feel free to reach out!
As mentioned in our last blog post, the team behind the DMP Tool has been working on a rebuild of the application to improve usability, add new features, and provide additional machine-actionable features. To provide all of this advanced functionality, we needed to do a pretty big overhaul of the technology behind the DMP Tool, and it was a good time to give the design a more modern upgrade as well, adding new functionality while hopefully making existing features easier to use.
How we made the first drafts and tested them
Over the past few months, we’ve worked closely with a team of designers to create interactive wireframes—prototype mockups that allow us to test potential updates to the user interface without fully developing them. These wireframes are crucial for gathering feedback from real users early, ensuring that our vision for a better tool meets their expectations. While a lot of thought and planning went into these initial designs, we wanted to make sure people were finding the new site as easy and intuitive as possible, while still offering new, more intricate features.
To do this, we recruited three groups of people, 12 total, who work on different parts of the tool to test out these designs:
5 researchers, who would be writing DMPs in the tool
4 organizational administrators, who would be adding guidance to template in the tool
3 members of the editorial board or funder representatives, who would be creating templates in the tool
We recruited volunteers from the pilot project members, from our editorial board, from social media, and from asking those we recruited to share the invitation with others. We conducted virtual interviews with each person individually, where we let them explore the wireframe for their section, gave them tasks to complete (e.g., “Share this DMP with someone else”), and asked questions about their experience. For the most part we let people walk through the wireframes as if they were using it for real, thinking out loud about what they were experiencing and expecting.
What we found from testing
It was illuminating for the team to see live user reactions from these sessions, and watch them use this new tool we’re excited to continue work on.
We loved to hear users say how excited they were for a particular new feature or how much they liked a new page style. At times it could be disheartening, watching a user not find something that we thought was accessible, but those findings are even more important because it means we have an area to improve. We made a report about the findings after each group of users and worked with the designers on how to address the pain points. Sometimes the solution was straightforward, while other times we wrestled with different options for weeks after testing.
Overall, we found that people liked the new designs and layout and could get through most tasks successfully. They appreciated the more modern layout and additional options. But there were many areas that the testers identified as confusing or unclear. There are specific examples, with before-and-after screenshots, in the Appendix. Some of the top changes made revolved around the following areas:
Decreasing some text in areas that felt overwhelming, moving less important information to other pages or collapsed by default
Adding some text to areas that were particularly unclear, such as what selecting “Tags” for a template question would do
Connecting pages if people consistently went somewhere else, such as adding a link to sharing settings on the Project Members page since that’s where people looked for it first
Moving some features to not show until they’re needed, such as having Visibility settings as an option in the publishing step and not the drafting step
Clarifying language throughout when things were unclear, such as distinguishing whether “Question Requirements” was about what the plan writer was required to write when creating their DMP or whether that was about the template creator marking whether a question is required or had display logic
Having additional preview options when creating a template or adding guidance to understand what a question or section would look like to a user writing a DMP
Making certain buttons more prominent if they were the primary action on a page, like downloading a completed DMP that originally was hard to find
Even though the main structure worked well for people, these small issues would have added up to a lot more confusion and obstacles for users if we hadn’t identified them before releasing.
Wrapping up and moving forward
The whole team learned a ton from these sessions, and we’re grateful to all the participants who signed up and gave their time to help us improve the tool. This sort of testing was invaluable to find areas to improve – we made dozens, if not hundreds, of small and large changes to the wireframes based on this testing, and we hope it’s now much better than it was originally. We’re still working on updates as we build our designs for more areas of the site, but feel better now about our core functionality.
If you’d like to be invited to participate in surveys, interviews, or other feedback opportunities like this for the DMP Tool, please fill out this brief form here: Feedback Panel Sign-Up. For anyone that signed up but wasn’t selected for this round, we may reach out in the future!
We loved seeing how excited people are about this update, and we can’t wait to share more. The most common question we get is – when is it releasing! That’s going to be quite some time, and we don’t have more to share yet, as we’re still too early in the development process. But stay tuned here for more updates as we do!
We want to thank Chan Zuckerberg Initiative (CZI) for their generous support for rearchitecting our platform. We wouldn’t be able to make all of these helpful updates along with our back-end transformations without it.
Appendix: Specific Examples
Important note: The “updated wireframes” shown here are not final designs. We have not yet completed a design pass for things like fonts, colors, spacing, and accessibility; this is just a quick functionality prototype so we could get early feedback. Even the functionality shown here may change as we develop based on additional feedback, technical challenges, or other issues identified. Additionally, these wireframes are mockups and do not have real data in them, so there may be inconsistent or incorrect info in affiliations, templates, etc; we were focused on the overall user interface in testing, not specific content.
Sharing settings
For those who want some more details and specific examples, here are a few of the top areas of confusion we found:
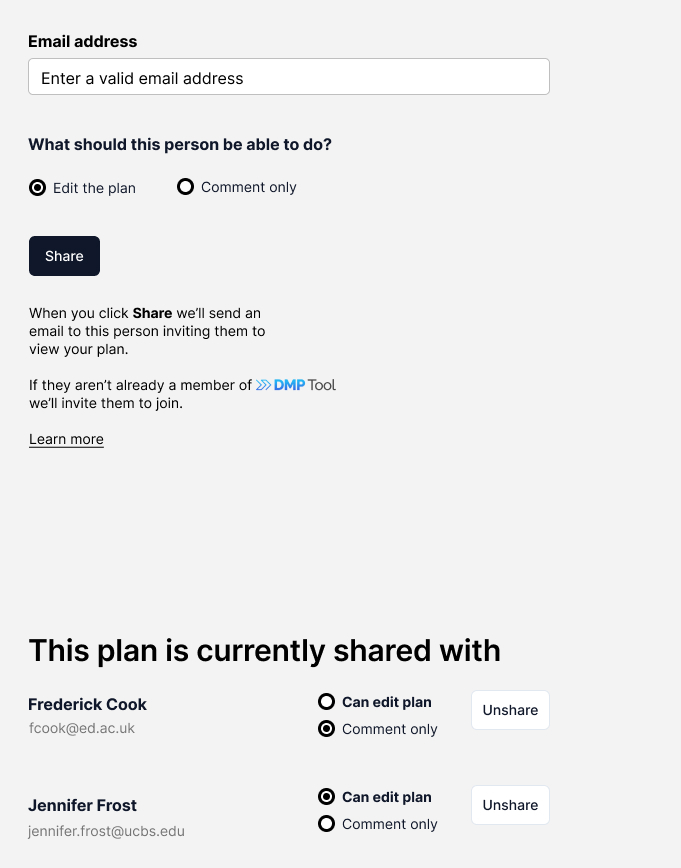
There was sometimes confusion in how to share a plan with others, and what the distinction is between a Project collaborator (e.g., another researcher on the grant who may not be involved in the DMP) and a DMP collaborator (e.g., a peer who is giving feedback on writing the DMP but not on the project). The current live tool has both “Project Contributors” and “DMP Collaborators” on the same page which we thought contributed to this confusion, so we wanted to separate those who can edit the DMP into a separate Sharing section. However, testers had a hard time finding these sharing settings, and often went to the Collaborators page to grant DMP access. So, we added a link to these settings where people were looking (the new section in the green box), and added more detail to the sharing page about whether they were invited or had access due to being a collaborator, changed some language within this like “Collaborator” to “Project Member,” with the option to change access.
Current tool:
On the current tool, these two types of collaborators are on one page.
Initial wireframes:
The Collaborators page in the initial wireframes, which was part of the overall project details and was not related to sharing access to the DMP itself.A separate Sharing page on the plan itself had sharing settings, and was completely distinct from Collaborators.
Updated wireframes:
This page was renamed to Project Members for clarity, with a link to the page for sharing access to the DMP since so many people looked for it here.This page was updated to give more information and control on invitations, and to make clear if people were added on because of an invite or because they were a project collaborator.
Card layout
Many parts of the tool used a new, more modern card format for displaying lists of items to choose from. This allowed us to show more information than in a list, and adapt to smaller screens. However, we saw in some areas that people had trouble scanning these cards to find what they were looking for, like a plan or template, when they expected to search in alphabetical order.
For example, picking a template in the first draft used a boxier card format. People found it harder to find the template they were looking for, since they wanted to quickly scan the titles vertically. So we changed it to a different format that should be easier to scan, even if it doesn’t show as many on one page. Note we also now have the option to pick a template other than from your funder, a common request in the current tool.
Current tool:
Currently, selecting your funder brings up a list of templates with no other information, and you can’t select a different template.
Initial wireframe:
This format allows more information if we want to add details that might help people pick the right template.
Updated wireframe:
This update still allows us to show more information, but the vertical layout means a person’s eyes can move in the same spot down the list to scan titles more easily if they know what they want.
Flow through the tool
People appreciated that they could move around more freely in the new design, as compared to the more linear format of the current tool. However, that also occasionally made people feel “lost” as to where they were in the process of writing a DMP. Especially as there is now a “Project” level above each plan to help support when people have multiple DMPs for the same research project. So we added more guidance, breadcrumbs, and navigation while still allowing the freedom of movement throughout the process.
For example, while writing a plan, users will now be able to see the other sections available and understand where they are in the Project tree. We also reduced some of the text on screen due to people feeling overwhelmed with information, putting some best practices behind links that people can visit if they wish to, and moved the Sample Answer people were most interested in to above the text box for better visibility.
Current tool:
The current tool has more distinct phases from writing a plan to publishing. In this view, a person is answering a single question and then would move on to the next.
Initial wireframe:
In our first draft, people clicked into each question rather than having all one one expandable page. But people weren’t always sure where they were in the process or how to get back.
Updated wireframe:
We added the navigation seen on the left and top here to allow people to see what else is in the plan and more easily get to other sections or the Project. We are also still working on how to reduce how much text is on the screen at once, for example by minimizing the guidance, but this is not final. We also moved the sample text above the question and removed the answer library for now.
Layout changes
In addition, there were tons of small changes throughout, changing layouts, wordings, and ordering of options in response to areas of confusion. Some places we scaled back a bit of functionality since the number of new options were overwhelming, while other places we added a bit more that people needed.
In the first draft of the wireframes, the visibility settings of the plan were on the main overview page of the plan. This was concerning to users since they were still drafting at this stage, and even if they may want it public once they published it, the setting in this location made it seem like it was public now. Instead we added a status and setting on the overview page, but the visibility setting does come up until a person gets to the Publish step, somewhat like the current tool that has those options later than in the plan writing stage.
Current tool:
Currently, setting visibility is later in the “Finalize” stage.
Initial wireframe:
In the first draft, this visibility settings were on the main plan page, which made people think it was public already as opposed to that it would be public once published.
Updated wireframe:
The updated main page, with many changes based on feedback, including visibility as a status on the right, which isn’t set until it is published, and more control over changing project details per plan.Now, visibility is set only once a person goes to publish their DMP.
We made similar change to creating a template, moving the visibility settings to be selected in the publishing stage instead of being in a Template Options menu people didn’t always see right away. They expected to set that visibility at the time they published it, so that’s where we moved that option to be, consistent with how the plan creation flow works.
Over the past 13 years, the DMP Tool has grown from a grassroots tool beginning at 8 institutions to one that serves thousands of universities across multiple continents. We’ve had a few big milestones in that time, such as adding the ability to register a DMP-ID and publish a DMP publicly, and creating the admin interface to allow universities to provide custom guidance on templates. The tool started in response to new requirements from U.S. funders for data management plans (DMPs; also known as data management and sharing plans–DMSPs), and our growth follows the research and library communities’ needs in this area.
Adding Machine-Actionable Functionality
Now, it’s time for our next big milestone in the DMP Tool: fully machine-actionable data management and sharing plans (maDMSPs). In 2022, the U.S. CHIPS and Science Act was signed into law, requiring DMPs submitted to the National Science Foundation (NSF) to be “machine-readable.” Machine-readable, or actionable, means that information is structured in a way that enables automatic connections and transformations without the need for manual intervention.
Excerpt from the CHIPS & Science Act, referring to NSF-funded research
On the current DMP Tool, some parts of the DMP have been made machine-actionable already, such as the DMP-ID and metadata. When you go to a registered DMP’s landing page, like this public plan for example, you see structure information like title and contributors pulled from a database. Other systems can work with that information through our public API, allowing for integrations with various research applications.
Now, we want to make all parts of the DMP – such as the narrative responses to the questions describing the plan – machine-actionable, and open up more tooling to work with structured maDMSPs, as was outlined in a Dear Colleague letter in 2019.
There are many benefits to maDMSPs, such as:
Having persistent identifiers that allow tracking of data publications and connections to other PIDs, like ORCIDs and ROR and DOIs
Creating opportunities for sharing information about DMPs between different campus units
Allowing integrations with research systems, like electronic lab notebooks, that can help researchers use DMPs in existing workflows
Establishing links to research outputs, like published datasets, that came from a DMP, to help link work and track compliance with the statements in a DMP
Rebuilding the DMP Tool
To implement these major changes, we realized a significant overhaul of the current DMP Tool was needed to accommodate these new features and underlying structural changes. For years, the DMP Tool rebuild has been a regular discussion point; we’ve long recognized its areas for improvement and regularly fielded requests for specific features. However, our team of two had limited ability to implement many of our, and the community’s, grand ideas.
Fortunately, we were able to obtain funding from an NSF EAGER grant that allowed us to explore a rebuild of the application, which would allow us to develop these features of the new tool and bring about these needed changes.
Our official rebuild work kicked off in April 2024 with a week-long workshop with our new team of consultants led by Paula Reeves from Reeves Branding and Zach Antony from Cazinc Digital. During that week, we dove into every aspect of the current application, mapping out existing features and brainstorming how to incorporate new ones. This included the machine-actionable data and formatting required for interoperability and the structured metadata needed to fuel the creation of machine-actionable data management plans. We reviewed the existing architecture, explored user personas, and redesigned workflows to facilitate project-centric planning. We also focused on building and customizing templates, adding guidance tools, and ensuring accessibility as we outlined development timelines and workflows for future phases.
The seven team members at the rebuild kickoff meeting
We’re excited to also get in a few top feature requests as well as maDMSP functionality, though we will be rolling them out in stages and cannot get to everything. Some of the areas we have currently prioritized include:
Additional API functionality, such as the ability with unpublished or in-progress DMPs
Ability to upload and register existing DMPs
Improved account management, such as being able to add secondary emails
Increased flexibility in creating templates, such as additional question types and streamlined ability to copy templates
Finding and connecting DMPs to published research outputs like datasets
Improved notification, comment, and feedback systems
Since the kick-off, the designers have been developing wireframes for the new tool, while we’ve added some new machine actionable elements to the current DMP Tool for testing. We’ve been working with the Association of Research Libraries (ARL) on a pilot project with 10 institutions, funded by the Institute for Museum and Library Sciences, gathering feedback from their use of the tool and conducting interviews about their efforts developing local integrations. Our first visit was to Northwestern University, which can read more about on ARL’s blog, with more coming soon.
What’s next
To stay focused on delivering this work, and due to the site’s technological constraints, we will be limiting updates to the current application. We’ll prioritize resolving critical issues while taking feature requests as requests for the new site.
We can’t wait to share more information over time about this project as it develops. While it’s too early to announce a release date, we’re hopeful it will be sometime before the end of next year. We recently wrapped up user testing on the wireframes, and will have a blog post coming soon about what we found. We’ll also be sharing information at upcoming conferences, such as a talk at IDCC25 called “Piloting maDMSPs for Streamlined Research Data Management Workflows.” Keep an eye on this space, and sign up for our newsletter, to hear occasional updates about this work!
We want to also thank Chan Zuckerberg Initiative (CZI) for their generous support for rearchitecting our platform. The back-end transformations and refactoring activities were funded through their generous support.