This is a joint blog post between DMPonline and the DMPTool
In February we conducted our annual strategic planning meeting between DCC and CDL to discuss joint plans for the upcoming year. We were joined from DCC by: Kevin Ashley, Patricia Herterich, Magdalena Drafiova, Marta Nicholson, Ray Carrick, Angus Whyte, Diana Sisu and from CDL: John Chodacki, Marisa Strong, Catherine Nancarrow, Brian Riley and Maria Praetzellis.
This meeting was a follow up to our 2019 meeting, where we had a chance to meet for three days with our colleagues and we wanted to replicate this in our half day online meeting. This time around we had to swap to Zoom for the lovely city of Edinburgh and only met for a half day instead of three days. Nonetheless, we managed to accomplish some important high level planning discussions regarding the work of continuing our collaboration on the Roadmap codebase. In this blog post we provide you with the summary of what we discussed and share our plans for the coming months.
Celebrating the achievements of 2020
We all agreed that despite the many challenges of 2020 (not to mention the departure of Sarah Jones and Sam Rust), this was a very successful year for our collaboration. Our team of developers completed several large developments a few of which are highlighted below:
- Completed the Rails5 migration
- Developed an API that is compliant with the RDA Common Standard for DMPs
- Released a new feature allowing for conditional questions and notifications within DMP templates
- Improved the usage dashboard
- Integrated with Google Analytics
- Integrated with translation.io to facilitate several languages
Several new features surrounding machine-actionable DMPs were also released of the past year including:
- RORs Identifiers for research organizations
- Funder Registry Identifiers for funders
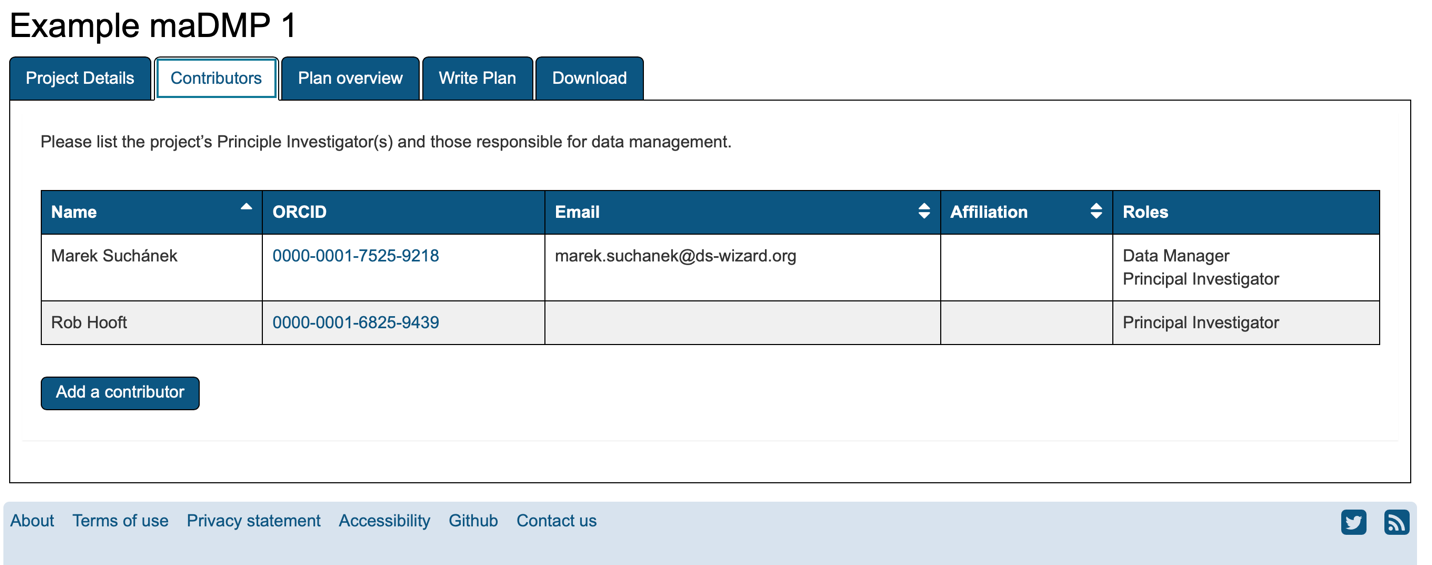
- ORCiDs for DMP creators and collaborators
- API compliant with RDA Common Standard Metadata Schema
- Ability to export plans as RDA Common Standard compliant JSON
Highlights of our 2021 Development Plans
During the first quarter of 2021, DMPonline will focus on consolidating the code base, making sure the various changes both the DMPTool and DMPonline team have developed over the past year are integrated and any new work is carried out on top of a shared code base.
UX Improvements
Based on the extensive usability testing that both DMPTool and DMPonline have conducted over the past year, we will select pieces of work that will have significant impact for both services. Initially we will focus on the creation of a new plan wizard making the creation of new plans and the selection of templates and appropriate guidance easier.
Expanded machine-actionable DMP features
- The ability to generate a unique identifier for a DMP with an associated landing page that connects the DPM to eventual research outputs
- A new Research Outputs tab will allow for more granular description of specific research outputs
- Integration with the Registry of Research Data Repositories (re3data)
- Integration with FAIRsharing
- Plan versioning
DMPRoadmap for funders
In 2021, we will also work on making DMPRoadmap more useful to funders. This will include:
- A different dashboard view
- Easier ways to integrate grant numbers and other funder specific information
- Tagging of institutional DMP templates as funder compliant
Other collaborations
The DMPonline team will also work with the TU Delft on a project that will integrate the system more with institutional login options to automatically get more information about users and use that to improve workflows and reporting for institutional admins.
RSpace integration
The electronic lab notebook, RSpace, and the DMPTool are currently working on an integration allowing for the bi-directional linking of data between DMPTool and RSpace. The first phase of this work is currently in development and utilizes OAuth so that users can connect accounts. Once we get this initial connection running, the team will look at bi-directional notifications and updates between the two systems.
For a more detailed description of our upcoming development plans please see our wiki page. This promises to be another busy but exciting year of work for both teams and we look forward to continuing to share our progress with you!