A few months back, we announced a new DMPTool NIH Template Working Group focused on supporting the upcoming NIH requirements for data sharing. Since then, this hard-working group, chaired by Nina Exner of Virginia Commonwealth University, has collaborated to develop several new resources for the community.
Updated NIH-GEN Template
The updated NIH-GEN DMSP (forthcoming 2023) template (v6) follows the structure laid out by the NIH in the optional DMS Plan format and aligns with the NIH-recommended Elements of a DMS Plan. The DMPTool NIH Template Working Group augmented NIH notices and other policy documents with additional sample language and guidance designed to help researchers create DMS plans. The new NIH-GEN DMSP (forthcoming 2023) template also includes guidance for data covered under the Genomic Data Sharing (GDS) policy, as NIH now expects a single data sharing plan to satisfy both the GDS Policy and the DMS Policy (NOT-OD-22-198).
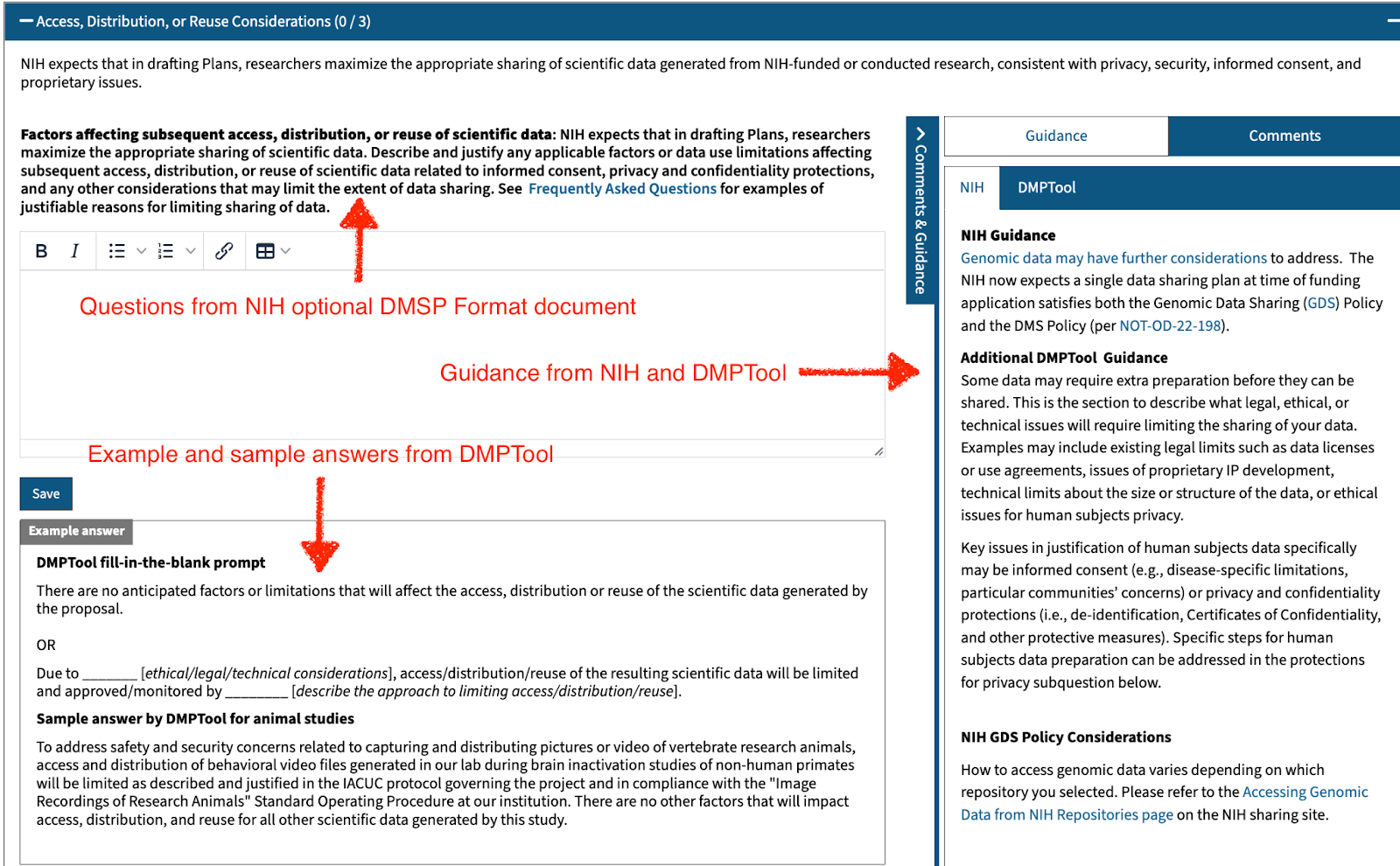
Test out the new template by creating a plan. Or, preview the new template by downloading a PDF version with sample language and guidance included.
DMPTool administrators can customize this (or any DMPTool template) and add institution-specific guidance and sample language. Instructions on how to customize templates and a short video tutorial are available. Any institutions with existing customizations will need to migrate to this new version of the template by publishing the template. Please see our documentation on the two steps required to transfer existing customizations.
The DMPTool will depreciate the older NIH templates (NIH-GDS: Genomic Data Sharing and NIH-GEN: Generic (Current until 2023)) on January 24. Any plans with these older templates will still be available, but new plans for NIH will be directed to the new template. After we make this switch, the NIH-GEN DMSP (Forthcoming 2023) template title will change to NIH-GEN.
New educational materials
The Education Sub-committee of the DMPTool NIH Template Working Group developed materials that institutions can use to promote the NIH requirements and use of the DMPTool. To support the increasing number of new medical centers and other institutions joining the DMPTool community, the Sub-committee produced a slide deck and flyers that institutions can utilize to train local researchers on using the DMPTool templates.
The Education Sub-committee also collaborated on a DMPTool training workshop held by the Network of the National Library of Medicine’s National Center for Data Services (NCDS). The first DMPTool workshop was held in December and broke attendance records. Betsy Gunia of Johns Hopkins led this training webinar, giving an excellent overview and DMPTool demonstration.
If you missed this first session, never fear! A recording of this session is available via the NNLM, and Jim Martin of the University of Arizona is giving a repeat session on February 15. Registration is available via NNLM.
Ongoing work
We will continue to iterate on the new templates, including the sample language and guidance provided, and welcome feedback from the community. As the NIH releases additional recommendations and guidance, we’ll continue incorporating these into NIH templates. As always, please reach out with any questions, suggestions, or feedback!