Cross-posted from ARL News and written by Cynthia Hudson-Vitale | cvitale@arl.org | August 4, 2023
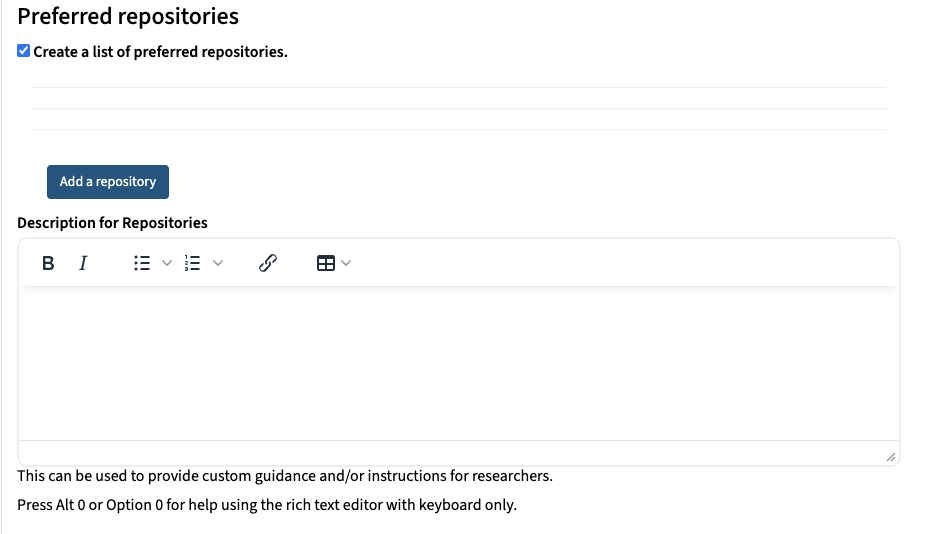
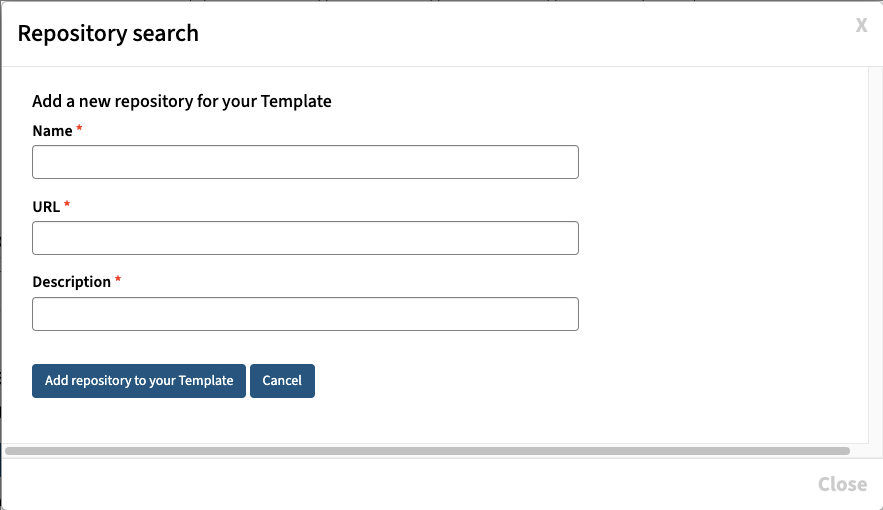
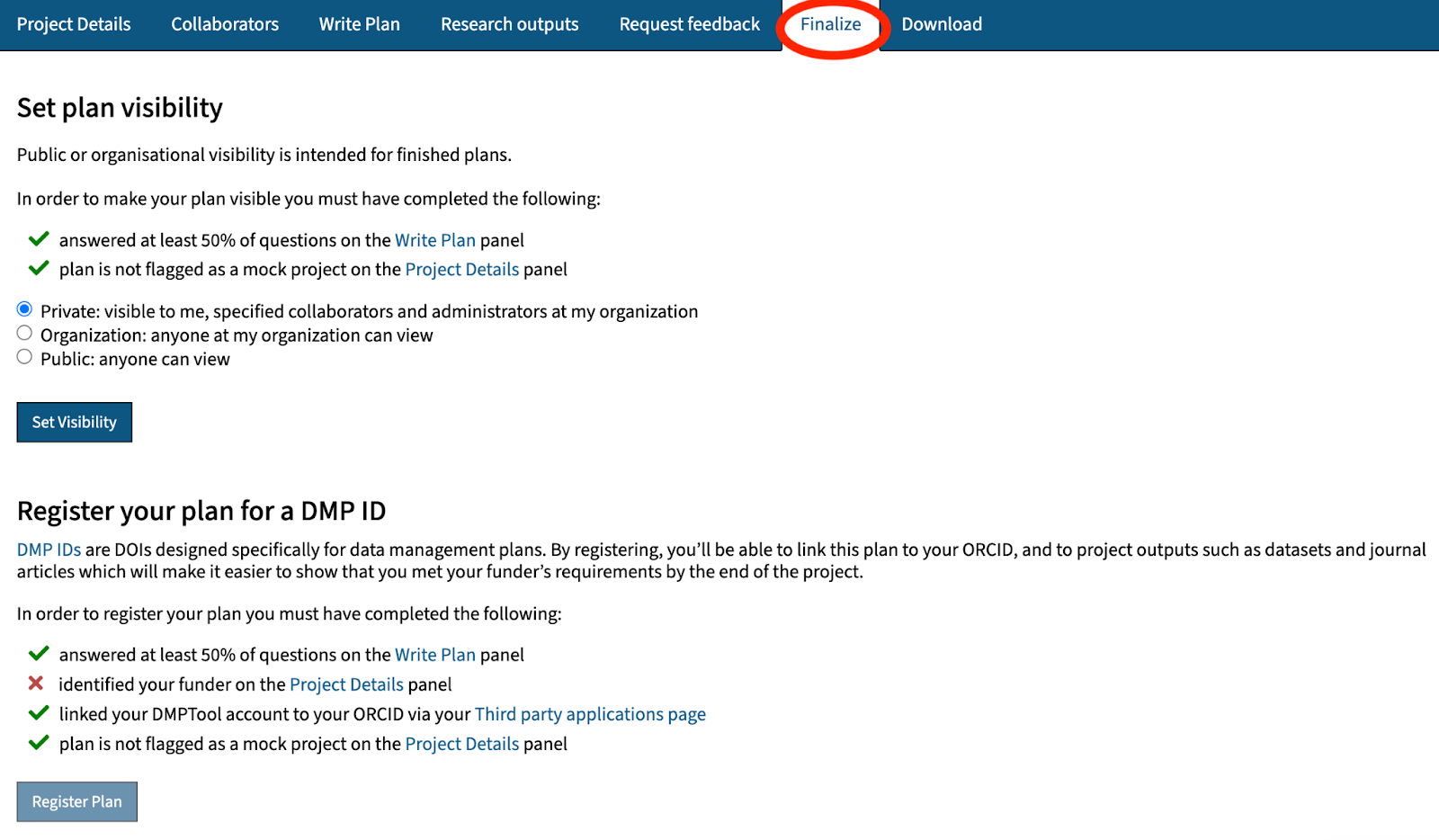
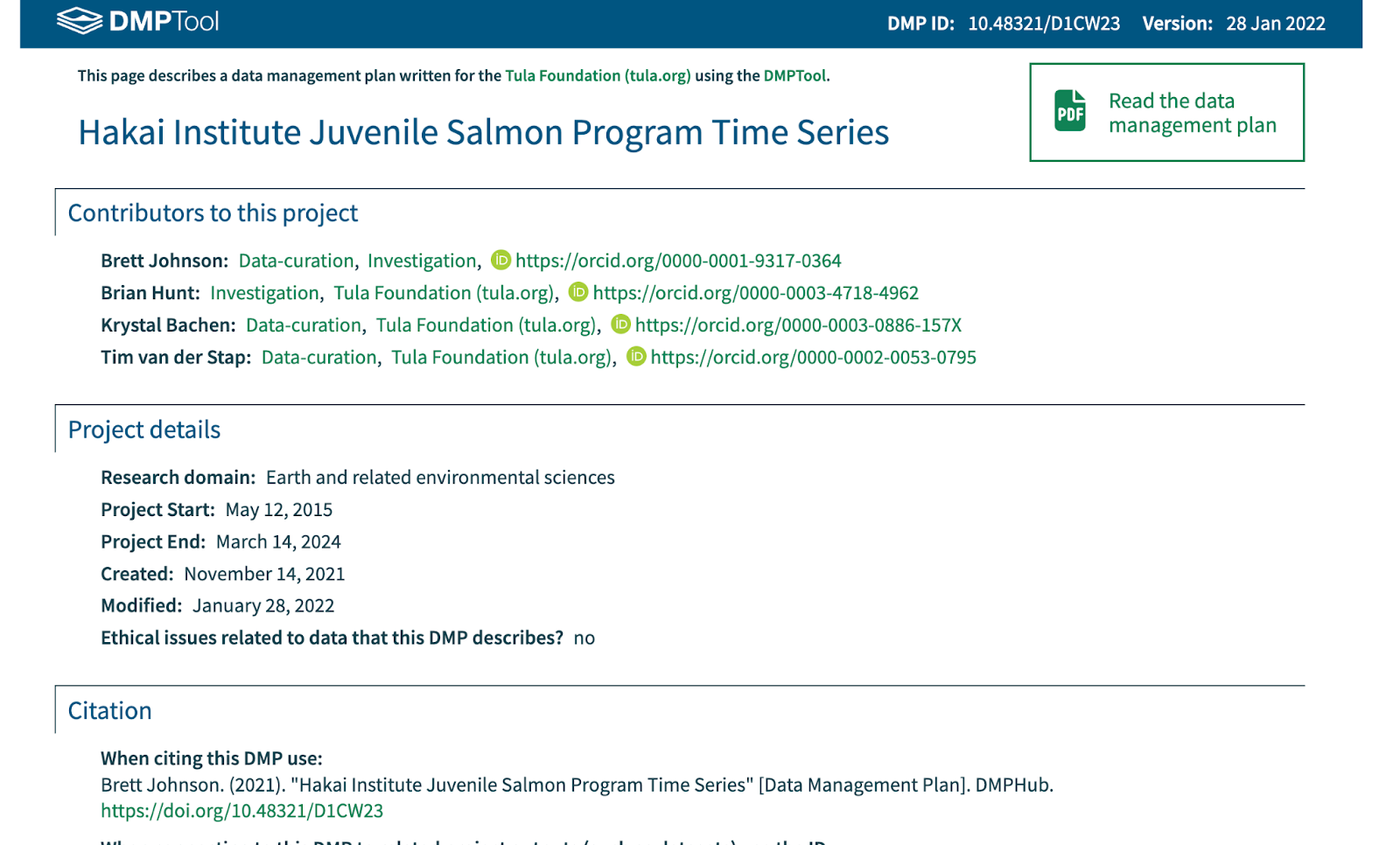
The Association of Research Libraries (ARL) and the California Digital Library (CDL) have received a $668,048 National Leadership Grant from the US Institute of Museum and Library Services (IMLS) to assist institutions in managing and sharing federally funded research data. This project will build a machine-actionable data-management plan (maDMP) tool by enhancing and developing new DMPTool features utilizing persistent identifiers (PIDs). CDL and ARL will work together to further strengthen institutional capacity for tracking research outputs by piloting the institutional integration of maDMPs across an academic campus and building community across institutions for maDMPs.
The promise of the maDMP is to be a vehicle for reporting on the intentions and outcomes of a research project that enables information exchange across relevant stakeholders and systems. maDMPs contain an inventory of key information about a project and its outputs with a change history that stakeholders can query for updated information about the project over its lifetime. By incorporating open persistent identifiers (PIDs) into DMPs and leveraging all DMP metadata for interoperability across infrastructures, institutions—and specifically libraries—will be better equipped to track and manage their institutional research data products.
CDL and ARL have collaborated before on advancing PIDs and maDMPs, including joint efforts on the 2019 National Science Foundation (NSF) grant Implementing Effective Data Practices that led to stakeholder recommendations for collaborative research support. The new IMLS project builds on this prior work by piloting maDMP workflows in the DMPTool, gathering feedback from partner institutions, and iterating on maDMP features to put those recommendations into practice at scale.
“We are thrilled to work with ARL on this timely project to advance open science by utilizing machine-actionable DMPs,” said Günter Waibel, associate vice provost and executive director, California Digital Library. “Facilitating the sharing and tracking of research data furthers our goals of supporting open scholarship and leveraging innovative technology to situate research data within an open knowledge graph of scholarly activity. We look forward to collaborating with ARL and partner institutions to build new tools and workflows to strengthen the research data ecosystem.”
“ARL is eager to engage its members and the broader research library community in testing new DMPTool features to improve cross-institution communications around open-science practices and research integrity,” said Mary Lee Kennedy, executive director, Association of Research Libraries.
In addition to developing DMPTool workflows to link research outputs and track relationships, this project will also work with four institutions to pilot the new features and improve capabilities. The call for institutional teams will be distributed in the next few months. Stay tuned for information on community calls and other project updates.
About the Association of Research Libraries
The Association of Research Libraries (ARL) is a nonprofit organization of research libraries in Canada and the US whose vision is to create a trusted, equitable, and inclusive research and learning ecosystem and prepare library leaders to advance this work in strategic partnership with member libraries and other organizations worldwide. ARL’s mission is to empower and advocate for research libraries and archives to shape, influence, and implement institutional, national, and international policy. ARL develops the next generation of leaders and enables strategic cooperation among partner institutions to benefit scholarship and society. ARL is on the web at ARL.org.
About the California Digital Library
The University of California (UC) founded the CDL in 1997 to take advantage of emerging technologies that were transforming the way digital information was being published and accessed. Since then, in collaboration with the UC libraries and other partners, we assembled one of the world’s largest digital research libraries and changed the ways that faculty, students, and researchers discover and access information. In partnership with the UC libraries, the CDL has continually broken new ground by developing systems linking our users to the vast print and online collections within UC and beyond. Building on the foundations of the Melvyl Catalog, we developed one of the largest online library catalogs in the country. We saved the university millions of dollars by facilitating the co-investment and sharing of materials and services used by libraries across the UC system. We work in partnership with campuses to bring the treasures of our libraries, museums, and cultural heritage organizations to the world. And we continue to explore how services such as digital curation, scholarly publishing, archiving, and preservation support research throughout the information life cycle. Serving the UC libraries is a vital component of our mission. Our unique position within the university allows us to provide the infrastructure and support commonly needed by the campus libraries, freeing them to focus their resources on the needs of their users. Looking ahead, the CDL will continue to use innovative technology to connect content and communities in ways that enhance teaching, learning, and research. CDL is on the web at cdlib.org.
About the Institute of Museum and Library Services
The Institute of Museum and Library Services is the primary source of federal support for the nation’s libraries and museums. We advance, support, and empower America’s museums, libraries, and related organizations through grantmaking, research, and policy development. IMLS envisions a nation where individuals and communities have access to museums and libraries to learn from and be inspired by the trusted information, ideas, and stories they contain about our diverse natural and cultural heritage. To learn more, visit www.imls.gov and follow us on Facebook and Twitter.
.