Like many in the research data management community, we have been closely following updates from the National Science Foundation (NSF) and National Institutes of Health (NIH) about changes to their data management and sharing plans (DMSPs, also known as DMPs).
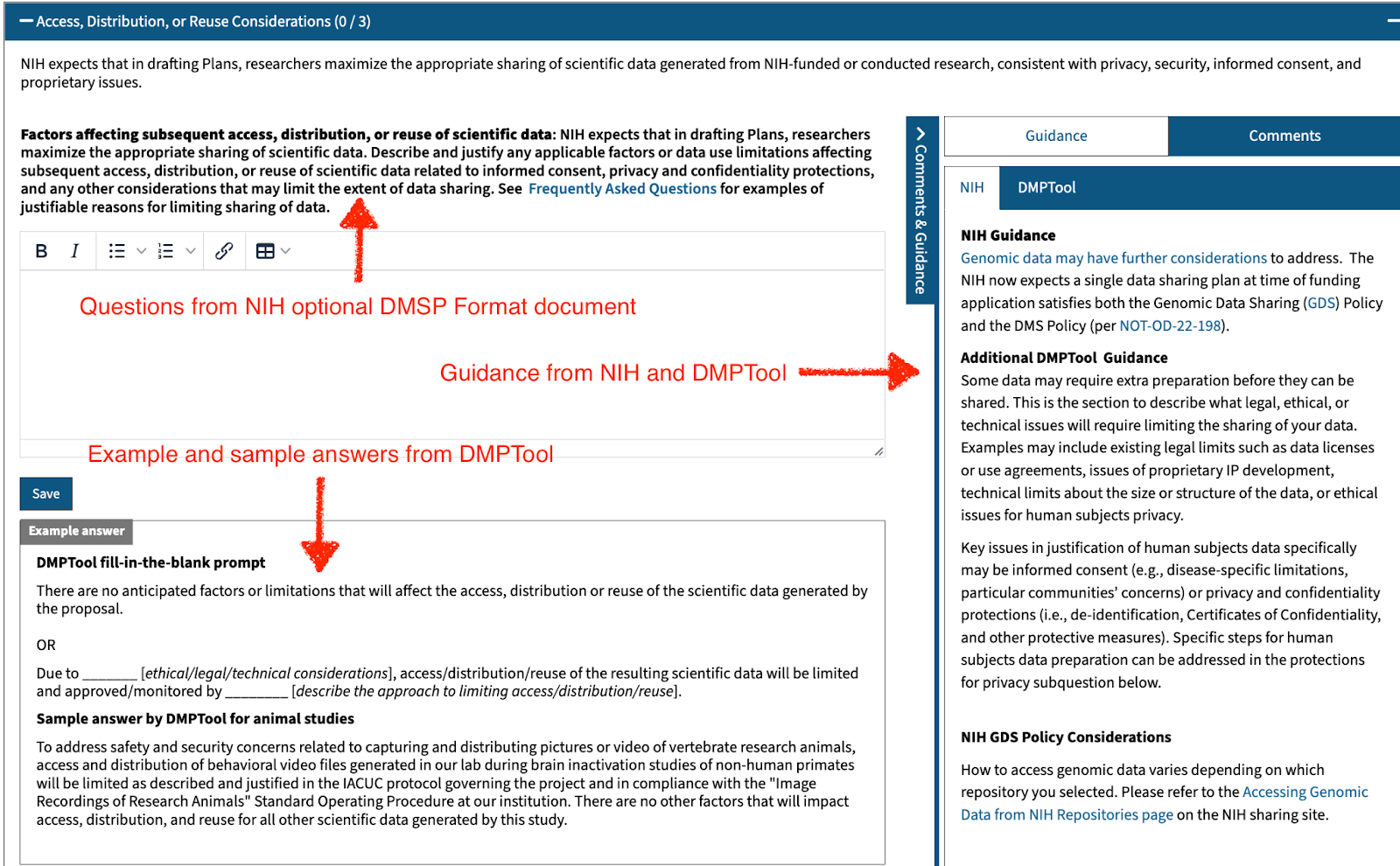
For those not aware, both the NSF and NIH are moving away from free-form narrative document DMSPs towards more structured, standardized forms, which can then potentially be embedded directly into their proposal systems. NSF announced that their DMSPs will, starting on April 27th 2026, be completed as a form on Research.gov rather than uploaded as a separate document. NIH is also making a major change to their DMSP template starting May 25th 2026, also moving away from free-form text narrative to mostly Yes/No questions about data sharing, plus a list of expected outputs and their intended repositories and a space to explain any exceptions to data sharing.
These changes reflect a broader shift on how funders approach data management planning. Rather than narrative documents, DMSPs are becoming structured inputs that can be more easily reviewed, compared, and in some cases tracked over the course of a project.
Community Impact
We are happy to see a move towards structured, machine-actionable questions over free text and reducing burden on researchers applying for grants. However, these changes have the potential to disrupt the way data management and planning is done throughout the research lifecycle.
- NSF’s new form may include the standard sections recommended in a DMSP, but the fact that it will only be accessible on Research.gov may make it harder for collaboration between researchers and data librarians to take place.
- NIH’s form will still be uploaded as a document as far as we are aware, but limiting to mostly Yes/No questions may take away much of the planning that needs to happen before data is collected.
We understand both these updates are new and will undergo evaluation and feedback periods – we look forward to working with NSF and NIH to see how these new forms perform and if there are areas of improvement for the future.
The two main areas the DMP Tool team will be watching is cross-institutional communication and interoperability. In our experience, researchers and grants teams value personalized university guidance and the ability to collaborate with local data librarians and research IT teams to get feedback on their DMSPs. These new changes will require a shift in the way the community works but may also require further refinement from the agencies.
We also hope to see more investment in interoperability in the future. Locking the DMSP information into a closed system without an API risks creating a new silo of important research information that will make it harder for other researchers to find and track data outputs from funded research. We hope that the agencies look for new ways for researchers to engage with their platforms that enable these types of interoperability and connectivity.
Adjusting to new workflows
While the DMP tool team continues to understand the implications of these new workflows, we are also committed to meeting the needs of our communities. Many have reached out to ask specific questions around how we will adjust the tool to work with NSF and NIH’s new approaches.
- For NSF, as soon as the final version of the Research.gov form is available, we will implement a copy of it into the tool. People who complete their DMSP for NSF in the DMP Tool will still be able to use its collaboration and guidance for help filling it out, though at the end they will likely need to copy/paste the information into the Research.gov form rather than export as a PDF. Regardless, the key features that support collaboration and communication will still be available for institutions to use in NSF proposal consultations.
- For NIH, we have already started work implementing the new form based on the preview provided. The questions are already entered, and we’re working with members of our DMP Tool Editorial Board to add appropriate guidance, recommendations, and relevant policies to the elements. As soon as the NIH form is finalized and we have that entered, we will publish it on the DMP Tool so researchers can start to use it for upcoming submissions, and organizations can start adding customizations and extra guidance if they wish.
Stay updated on the latest! We will message our status and next steps on this blog, our LinkedIn account, and direct emails to all member organization contacts.
Implications on our ongoing platform development
As we described above, in the immediate future, we will continue to support creating DMSPs in the tool for NSF, NIH, and many other US and international funders however they structure their templates. In parallel, our rebuild work continues on. We will be taking these new announcements as opportunity to reflect and adjust our priorities and timelines. We think that many of the new functionalities coming in the new tool fit well with this evolving landscape. For example, the new tool will support creating a Project that can house multiple related plans and allow uploads of plans created elsewhere. This could allow, for example, people to upload a copy of the plan they submitted to NSF to the tool, and house related plans within one research project. This allows for support of Data Security Plans, Software Management Plans, and other documents that many universities and field stations now require.
In the long term, we’re committed to evolving the DMP Tool to meet the needs of the community, even as those needs change. We will continue to have open conversations about how to properly prioritize and adapt our current efforts for the changes we see coming on the horizon.
Our core commitment is to serve and promote best practices in data management planning, and that goes beyond the document itself. We know that our community’s strengths are in the customized guidance, collaboration, and resources that we all bring together from researchers, funders, and universities into one place, and we think that is more valuable than ever. We will keep you all posted as we address the evolving landscape together!