Cross-posted from our UC3 blog
Welcome to the second post of UC3’s New Year blog post series, where different services of UC3 take a look at the coming year. If you haven’t already read it, check out the first one on digital preservation.
Over in the world of Data Management Planning, we’ve got a lot of exciting work this year to share!
DMP Tool Rebuild
Our main project continues to be working on the rebuild of the DMP Tool. While we initially hoped to have it ready early this year, we’re now targeting the summer of 2026. This gives us more time to make sure it’s at a high level of quality, and also releases it at a time that will hopefully be less disruptive to people who teach classes using the DMP Tool. There’s a chance it will take longer than the summer though – we’re focused on quality over speed.
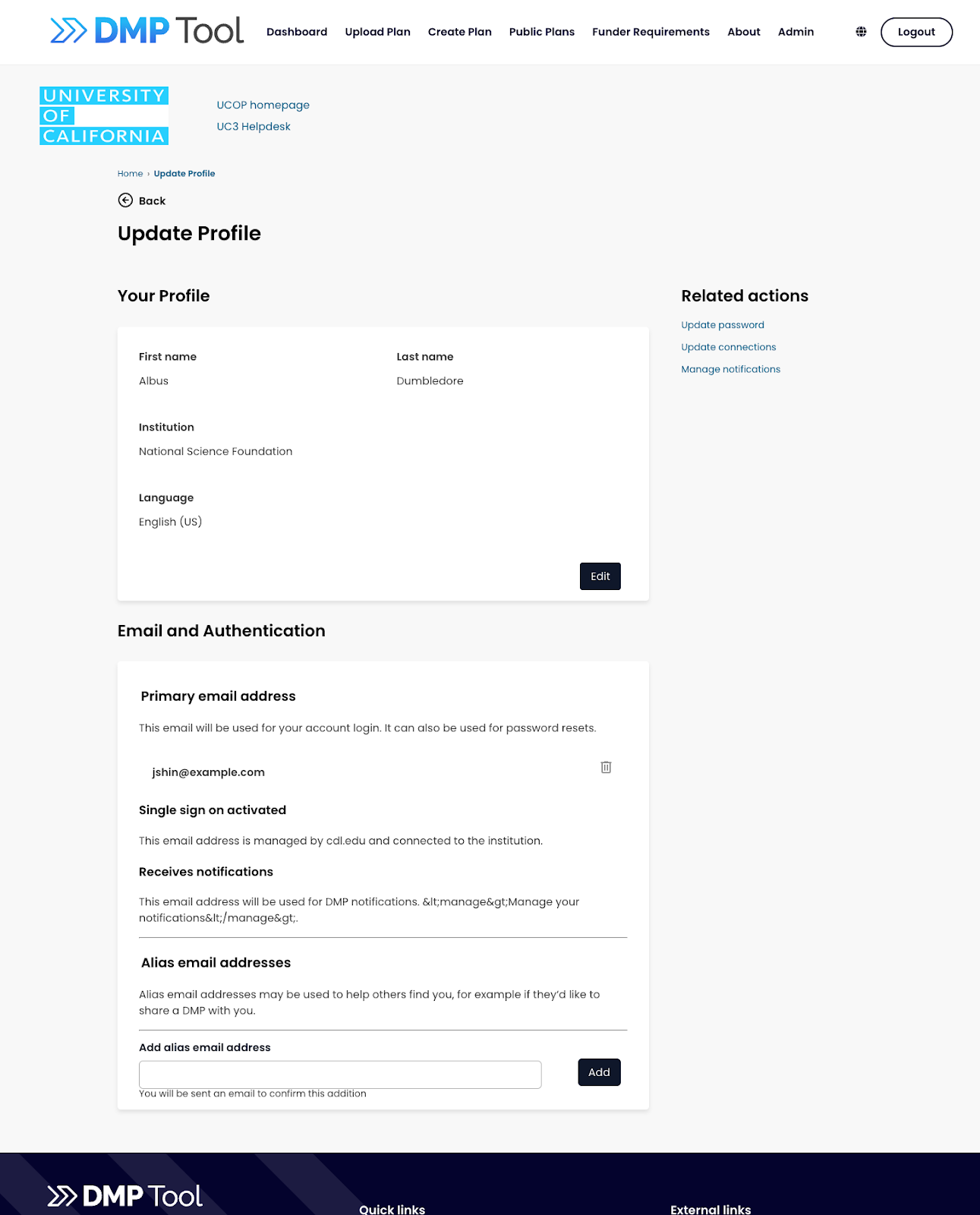
We’ve done 3 rounds of user testing so far on the site, and each time has given us a lot of valuable information. We’ve gotten a lot of positive feedback about new features we will be offering, such as alias email addresses, adding collaborators to templates, a revamped API, and much more. Other changes, though, have caused some confusion for people used to the current tool, and through testing we have found opportunities to improve the workflow and usability of the new site. These are the types of changes that mean the rebuild will take longer than initially planned to complete, but we think are worth the time to get right.

To keep updates about the rebuild in one place, we have a Rebuild Hub page on our blog. We’ll keep this page up to date with the latest information about the release date, FAQ, status updates, and more. We plan to make posts leading up to the new release showing the major changes and giving guidance to make the transition as seamless as possible. If you’d like to help with testing at any point, please sign up for our user panel to get invitations to future feedback sessions.
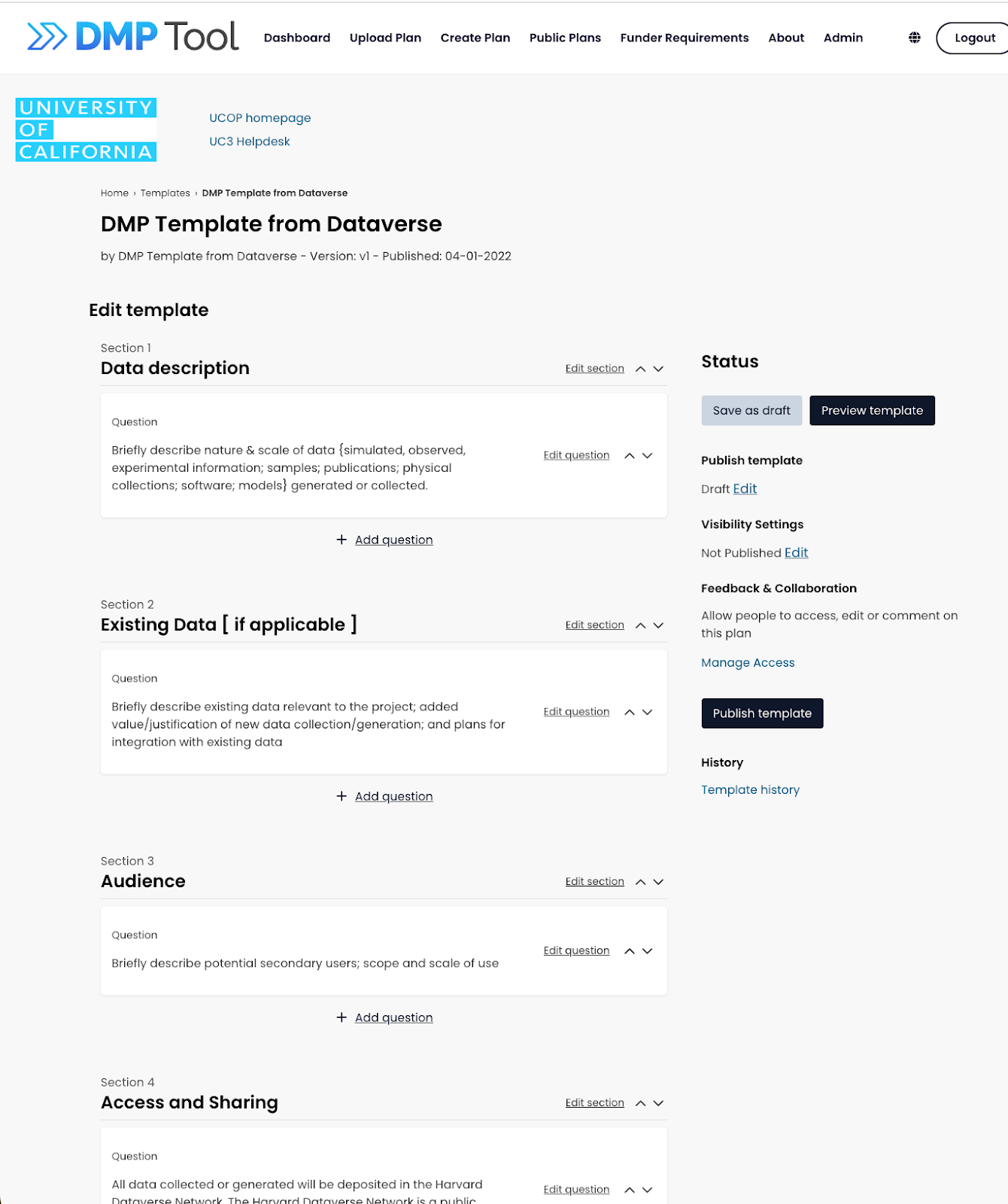
As we’ve said before, we’re limiting updates to the current tool so we can focus our limited resources on the rebuild; but of course we also want to keep the tool live and helpful during the transition. We’re fixing any major issues that come up, such as keeping it up to date with new ROR API and schema, and addressing user tickets as quickly as possible. We are trying to keep funder templates up to date as well, but the frequency of new information and potential changes has made it difficult to perfectly capture all updates to federal guidelines. We want to make sure we have the most relevant information possible on the tool without changing templates too often (as that can lose organization guidance), so we’ve been collecting updates from our Editorial Board members for a template release in the near future. If you see any instances where a template in our tool does not match a funder template, please reach to us by email so we can get it corrected.
Get Involved with API Integrations
With our rebuild is coming a complete revamped API to take advantage of our new machine-actionable functionality. We’re currently looking for partners that would like early access to our new API in order to develop new integrations for our rebuild. Our goal is that the new API can do anything the user interface can do, which means the sky (or more relevant, the cloud) is the limit for possible tools. If you’ve been wanting to connect to our API for some sort of automation that our current API did not offer the capability for, we’d love to hear from you. You can hear more about past pilot integrations and how to work with our API at this recording of our webinar from the Machine-Actional Plans pilot project. We’ll be following the common API standard being developed with the Research Data Alliance, meaning many integrations with our tool should work for other DMP service providers as well. If you have an idea for an integration you’d like to build on our new API, please reach out to dmptool@ucop.edu!
Matching to Published Research Outputs
We’ve talked before about a major project to use machine learning models to help match DMPs to their eventual research outputs, like datasets and software publications, to help make data from published DMPs easier to find and re-use. This work has continued and we plan to release it with the rebuilt DMP Tool. Since our last update, we’ve made some significant steps towards this goal, including:
- Moving the infrastructure onto our own servers to prepare for integration into the DMP Tool
- Adding new sources of data, such as grant award pages that list published outputs
- Getting the normalized corpus into OpenSearch to aid us in the matching process
- Expanding our ground truth dataset of true matches and non-matches to help test our matching algorithm
- Utilizing a Learning to Rank model that will improve over time as it learns from accepted and rejected matches
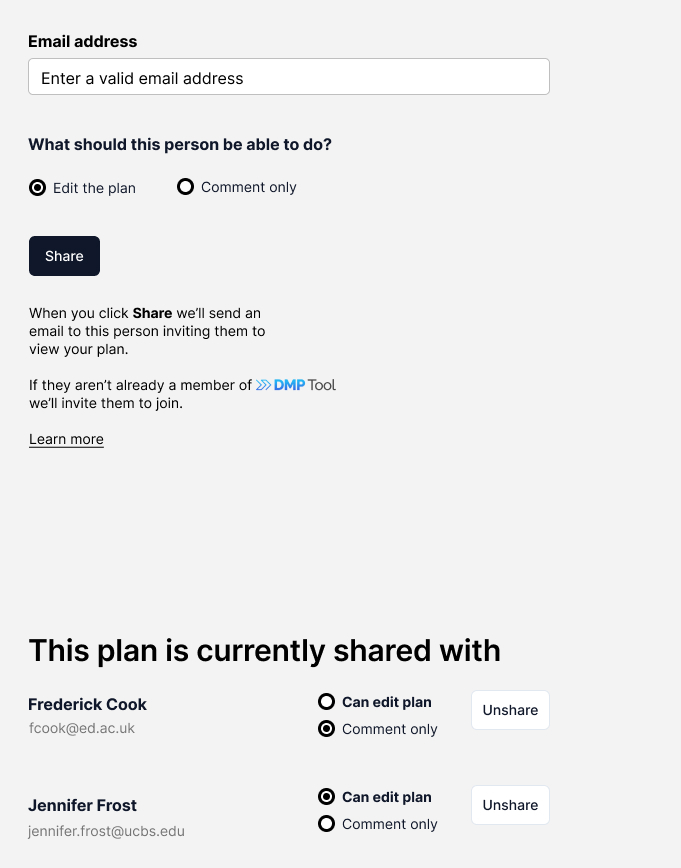
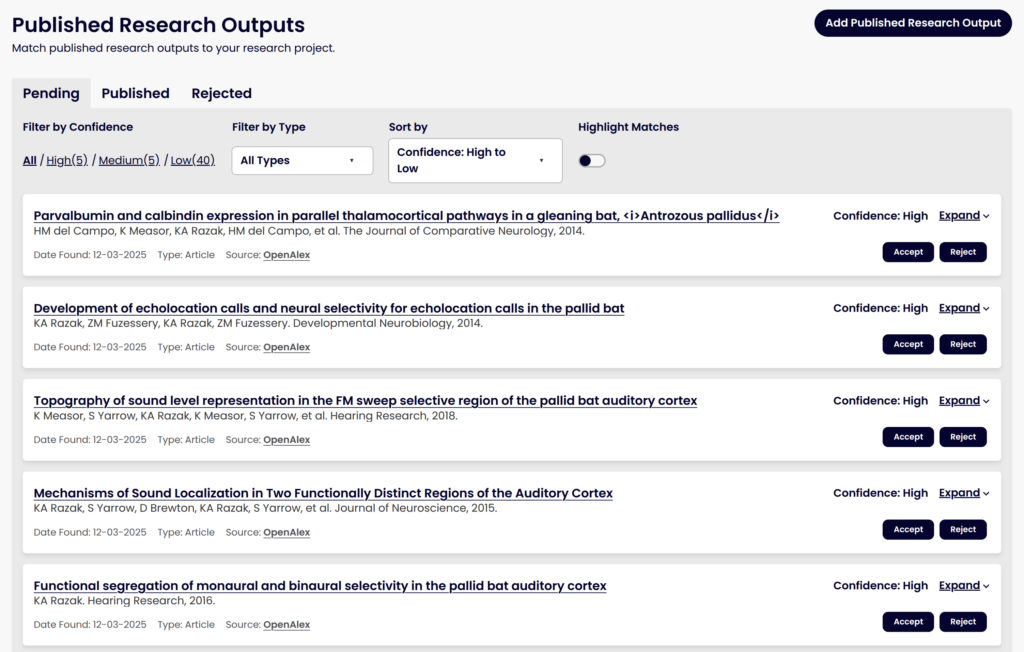
- Building out the user interface for how users will see potential matches and accept or reject them
Improvements we plan to work on over 2026 include:
- Adding in related outputs based on accepted outputs (i.e., finding matches to any Accepted works in addition to matching against the DMP itself)
- Looking at options to improve the matching algorithm, such as vector search with an embedding model
- Working with the COMET team on tooling that can extract award IDs from published outputs, which will improve the quality of matching to DMPs that include an award ID
We’re excited for people to get to use this tool with the rebuild and start accepting and rejecting potential matches so we can learn from this and improve the matching algorithm further over time. People will also be able to manually add DOIs as research outputs, like they can on the current tool, which will also help train the model over time on what we missed as potential matches. This will be available for all DMPs that have been published, i.e., registered for a DMP ID. Accepted works will be added to the metadata for the plan as related identifiers.
DMP Chef
Another exciting area we’re exploring is the use of generative AI to assist in writing Data Management Plans. We’ve partnered with the FAIR Data Innovations Hub to work on the DMP Chef, a project to explore using large language models (LLMs) to draft DMPs. Our goal is not to take away the key decisions in data management planning from a researcher, but instead to simplify the process as much as possible by asking a few critical questions, combining that responses with funder requirements that need to be met, and using those to produce a draft of a DMP for their review and edits.
We have promising early results, with both automated statistics and human evaluations showing the LLM-drafted DMPs can be comprehensive, accurate, and follow best practices. Commercial models are performing better than the open-source models, but since we want to remain open-source, we’re looking at ways to improve the open-source models through additional retrieval augmented generation and other options. And we’ll be testing carefully how accurate and helpful the output is, as well as looking at ways to help ensure researchers read and edit the plan as needed, rather than just accept the output right away.
| DMP Source | Overall Satisfaction rating (1-5) | Average Error Count per DMP | Accuracy in guessing LLM vs Human |
|---|---|---|---|
| Human | 3.1 | 7.2 | 65% |
| LLMs (combined) | 3.4 | 4.9 | 43% |
| Llama 3.3 | 2.6 | 7.5 | 70% |
| GPT-4.1 | 4.2 | 2.3 | 15% |
Over the course of 2026, we plan to keep testing and improving this model, starting with NIH and NSF plans. The ultimate goal is a general use model that can be used within the DMP Tool for any funder to get a first draft of either a whole DMP or specific sections a researcher is struggling with. We have a working prototype tool for DMP generation we will use for testing purposes, with integration into the DMP Tool planned for further out. If you’d like to be part of testing out this new tool, please sign up for our user panel.
Thanks for reading about our major initiatives for the year! Keep an eye out on this space for the next post in our series, about our 2026 plans for persistent identifiers.
We are grateful to the Institute of Museum and Library Services, the National Science Foundation, and the Chan Zuckerberg Initiative for each supporting core components of these initiatives.