
Building on the conceptual framework laid out in articles such as Ten principles for machine-actionable data management plans and prior blog posts covering such topics as what maDMPs are, what they can do to support automation, utilizing common standards and PIDs, and maDMPs as living documents, we are now moving into active development on the technical aspects of our NSF funded EAGER research project.
A phased approach: building a plan for maDMPs
The goal of our EAGER research project is to explore the potential of machine-actionable DMPs as a means to transform the DMPs from a compliance exercise based on static text documents into a key component of a networked research data management. This ecosystem will not only facilitate, but also improve the research process for all stakeholders.
We will be laying out the phases of work in the coming months and will continue to use this blog to keep the community informed of our progress, and to solicit your feedback and ideas.
Phase 1 Workplan

Phase 1 of of our research entails exploring the following three high level ideas:
- How to best restructure the DMPTool metadata to utilize the RDA Working Group Common Standard
- How to optimize the Digital Object Identifiers (DOI) metadata schema for DMPs
- How to best incorporate other Persistent identifiers (PIDs) into DMPs
Common Standards
The common data model for the creation of machine-actionable DMPs, produced by the RDA working group on DMP Common Standards, was recently released for community feedback. Our partners at the Digital Curation Center (DCC) have now implemented this model into the DMPRoadmap codebase. A big thank you to Sam Rust from DCC for his work on this! Those interested in learning more about the Common Standard in DMPRoadmap may want to view a recent webinar recording of Sam detailing this work. This was a fundamental step towards machine actionable DMPs, as it forms the foundation to enable information flow between DMPs and affiliated external systems in a standardized manner.
DOIs for DMPs
With our partners at the Digital Curation Center (DCC), we are working to incorporate the common standards into the shared DMPRoadmap codebase and our DMPTool development plans. As part of this work, we have partnered with DataCite to update their metadata schema to better support DMPs and to optimize a workflow for generating DOIs for DMPs. By relying on the DOI infrastructure, we will then be able to utilize the Event Data service from DataCite to record when assertions have been made on the DOI. More on the workflows surrounding this aspect of the project below.
DMPs and the PID graph
Projects such as Freya have been working to connect research outputs through a PID graph. A key question underpinning much of our work is how we can best leverage the PID graph (see Principle 5: Use PIDs and controlled vocabularies) within the DMP ecosystem. To connect DMPs to the larger PID ecosystem, our first phase will also include incorporating the following persistent identifiers into the DMP as a baseline for future work:
- Researcher IDs (ORCIDs)
- Funder IDs (FundRef)
- Research Organization IDs (ROR)
- re3data global registry of research data repositories
- As well as exploring the newly established Grant Id registry from Crossref
Phase 1 workflows
As discussed above, in Phase 1, we are building a system to mint DOIs for DMPs and creating a landing page for DMP DOIs to record updates to the DOI that occur over time. Although the system can be thought of as a giant API, pulling and pushing data from various sources, we are also building a landing page for these DOIs in order to visually demonstrate the types of connections made possible by tracking a research project over time from the point of DMP creation.
Below is a high level overview of this workflow and whiteboarding of its potential architecture. (For those that would like a more detailed view, please check out our GitHub).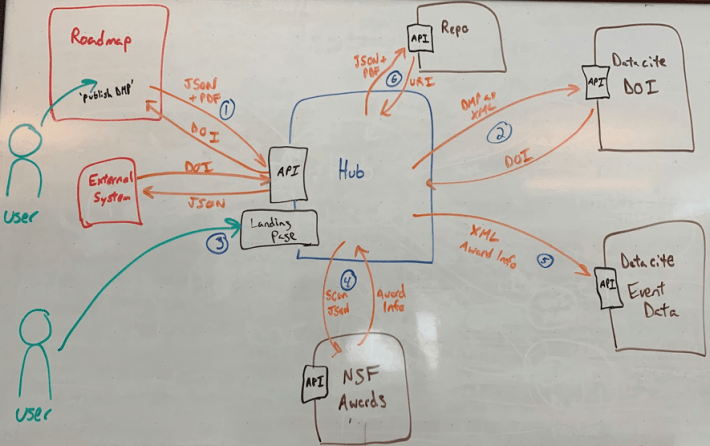
- maDMP system accepts common standard metadata from DMPTool (DMP Roadmap)
- maDMP system sends that metadata to DataCite to mint a DOI (which it then returns to the DMPTool)
- A landing page is generated for the DMP DOI
- A separate harvester application queries outside APIs to check for assertions recorded against the DOI. For this phase of work we will work with the NSF awards API, and return any award information into the maDMP system.
- The maDMP system then sends any award info returned to DataCite
Our goal is to leverage the work being done by the RDA Exposing DMP working group to help inform the privacy concerns of exposing certain types of assertions on this landing page.
Next Steps
Looking ahead, we plan to produce a basic prototype ready for testing and feedback by the end of October. I will be presenting on our work thus far at the upcoming RDA and CODATA meetings. During these meetings, I look forward to continuing our work with the RDA Common Standards Working Group (and to meeting many of those active in this space for the first time in-person)!
Once we establish the workflow to record assertions to a DMP DOI, our next phase of work will include pilot projects with domain-specific and institutional stakeholders to test the flow and integration of relevant information across services and systems. With these partners we plan to test how maDMPs can help track data management activities as they occur during the course of a grant project.
Finally, it’s important to note that all of our development work is being done in a test environment where we will continue to iterate for the next several months as we determine how best to deploy new features to the DMPTool and DMPRoadmap codebase.
Interested in contributing?
Lastly, we realize that maDMP is far from the most euphonious or creative name for this service (nor is our original idea of the DMPHub much better). We are open to any and all ideas for naming this work so if you have any ideas, however strange or off the wall, please do let us know. If we use your idea we promise to shower you with accolades for your denomination genius. Also, free stickers galore.
To review or contribute to the technical components of the project check out our GitHub. And most importantly, please send any and all feedback, questions, or ideas for names to maria.praetzellis@ucop.edu.

You must be logged in to post a comment.