We’re gearing up for a big year over at the DMP Tool! Thousands of researchers and universities across the world use the DMP Tool to create data management plans (DMPs) and keep up with funder requirements and best practices. As we kick off 2025, we wanted to share some of our major focus areas to improve the application, introduce powerful new capabilities, and engage with the wider community. We always want to be responsive to evolving community needs and policies, so these plans could change if needed.
New DMP Tool Application
Our primary goal for the year is to launch the rebuild of the DMP Tool application. You can read more detail about this work in this blog post, but it will include the current functionality of the tool plus much more, still in a free, easy to use website. The plan is still to release this by the end of 2025, likely in the later months (no exact date yet). We’re making good progress towards a usable prototype of core functionality, like creating an account and making a template with basic question types.
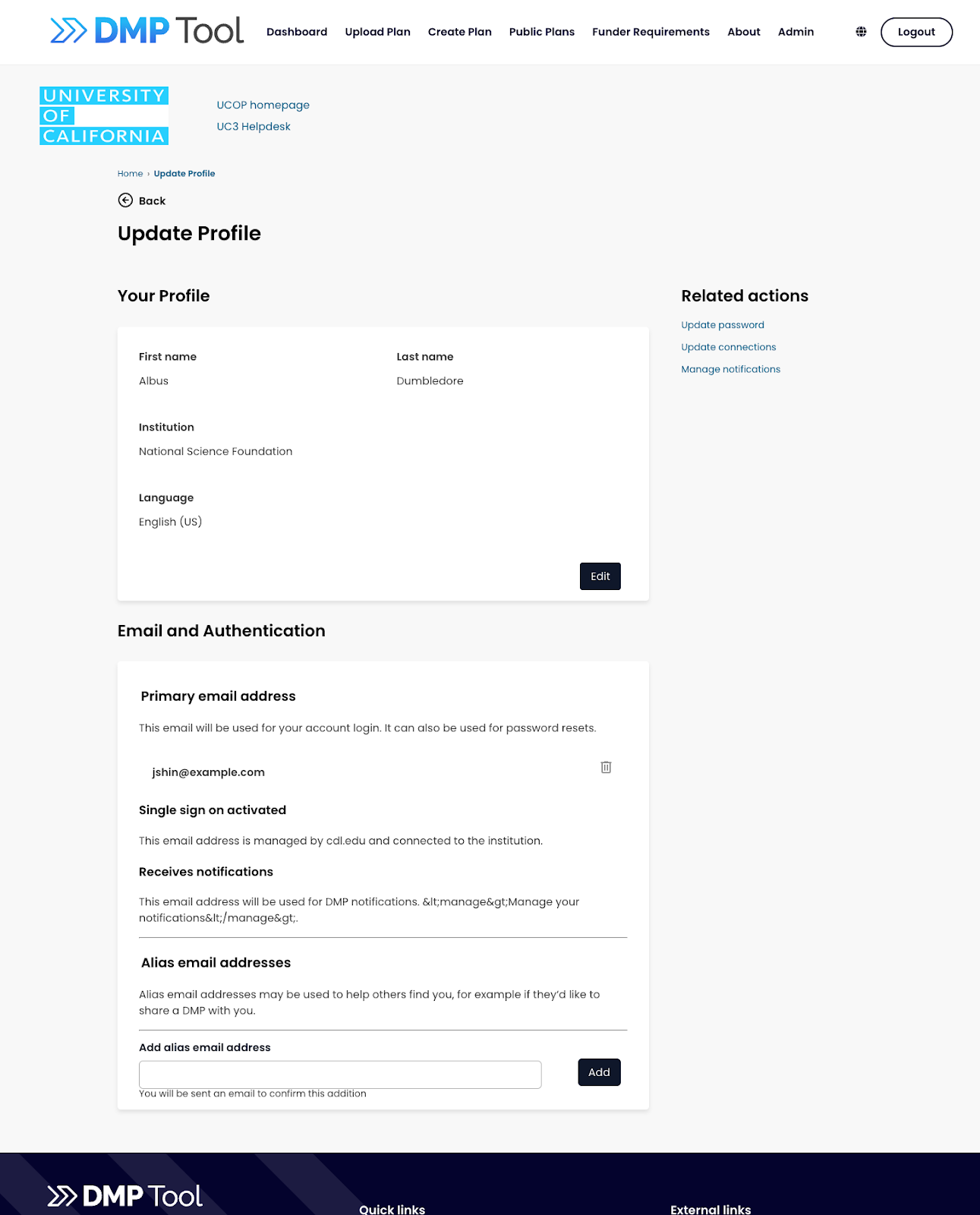
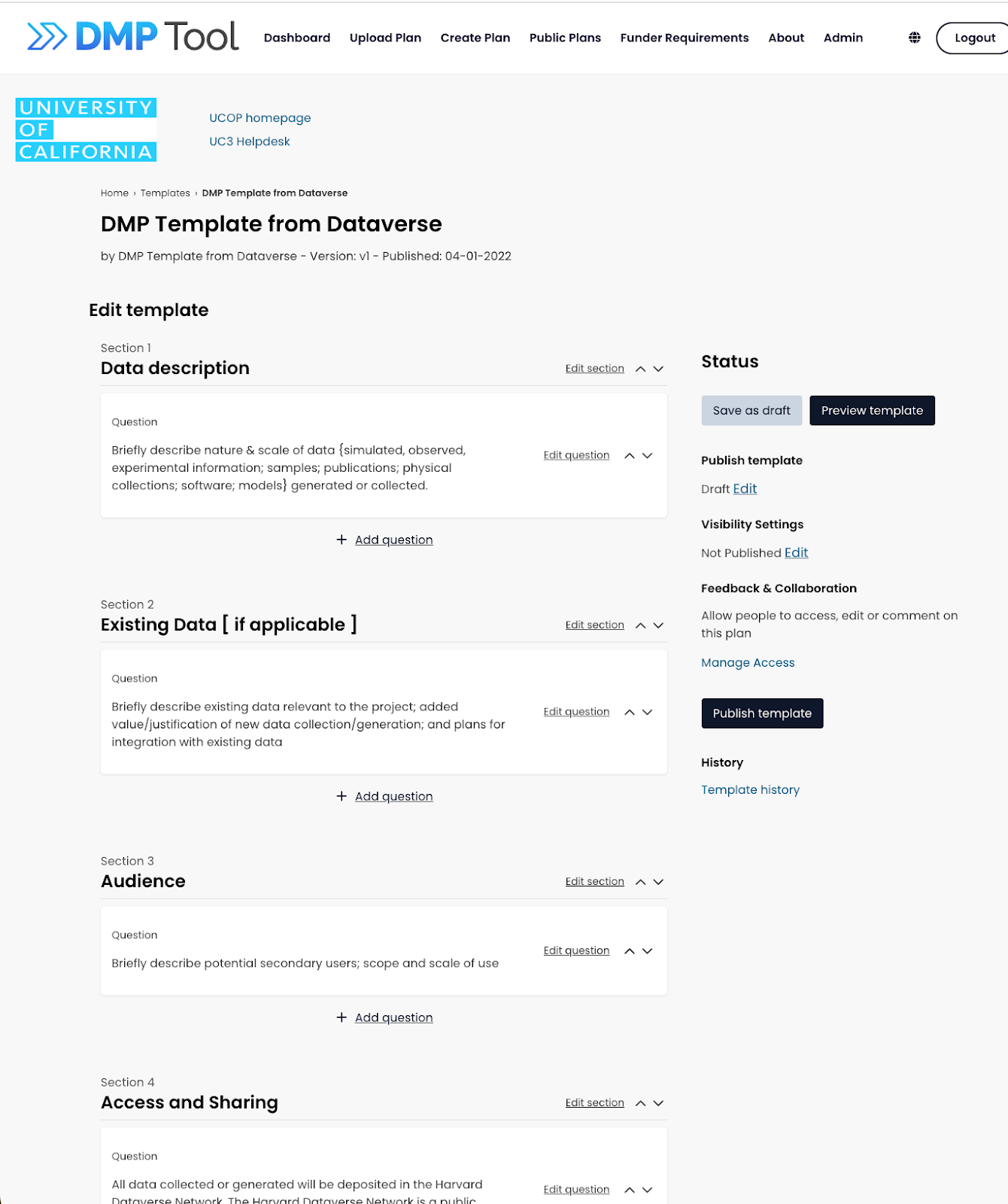
In-development screenshot of account profile page in the new tool. Page is not final and is subject to change.In-development screenshot of editing a template in the new tool. Page is not final and is subject to change.
Another common request is to offer more functionality within our API. For example, people can already read registered DMPs through the API, but many librarians want to be able to access draft DMPs to integrate a feedback flow on their own university systems. As part of our rebuild, we are moving to a system that is going to use the same API on the website as the one available to external partners (GraphQL for those interested). This will allow almost any functionality on the website to be available through the API. This should be released at the same time as the new tool, with documentation and training to come. Get your integration ideas ready!
Finally, we are continuing to work on our related works matching, tracking down published outputs and connecting them to a registered DMP. This is part of an overall effort to make DMPs more valuable throughout the lifecycle of a project, not just at the grant submission stage, and to reduce burden on researchers, librarians, and funders to connect information within research projects. It’s too early to tell when this will be released publicly on the website, but likely will come some time after the rebuild launch.
AI Exploration
While most of our focus will be on the above projects, we are in the early stages of exploring topics for future development of the DMP Tool. One big area is in the use of generative AI to assist in reviewing or writing data management plans. We’ve heard interest from both researchers and librarians in using AI to help construct plans. People sometimes write their DMP the night before a grant is due and request feedback without enough time for librarians to provide it. AI could help review these plans, if trained on relevant policy, to give immediate feedback when there’s not enough time for human review.
We’re also interested in exploring the possibility of an AI assistant to help write a DMP. We know many people are more comfortable answering a series of multiple choice questions than they are in crafting a narrative, and it’s possible we could help turn that structured data into the narrative format that funders require, making it easier for researchers to write a plan and keeping the structured data for machine actionability. Another option is an AI chatbot within the tool that can help provide our best practice guidance in a more interactive format. It will be important for us to balance taking some of the writing burden off of researchers while making sure that they are still the one responsible for the content within it.
These ideas are in early phases – it’s something we’ll be exploring with some external partners but likely not releasing to the public this year – however we’re excited about their potential to make best practice DMPs easier to create.
Community Engagement
While we’ll sometimes be heads down working on these big projects, we also want to make sure we’re communicating to and participating in the wider community more than ever. As we get towards a workable prototype of the new tool, we’ll be running more user research sessions. The initial sessions, reviewed here, offered a lot of valuable insight that shaped the current designs, and we know once people get their hands on the new tool they’ll have more feedback. If you haven’t already, sign up here to be on the list for future invites.
We also want to be more transparent with the community about our operations and goals. We’ve started putting together documents within our team about our Mission and Vision for the DMP Tool, which we’ll be sharing with everyone shortly. Over 2025, we want to continue to work on artifacts like those we can share regularly so that you all know what our priorities are. One goal is to create a living will, recommended by the Principles of Open Scholarly Infrastructure, outlining how we’d handle the potential winddown of CDL managing the DMP Tool. This is a sensitive area because we have no plans to wind down the tool, and don’t want to give the impression that its going away! But it’s important for trust and transparency for us to have a plan in place if things change, as we know people care about the tool and their data within it.
Finally, we’ll be wrapping up our pilot project with ARL this year, where we had 10 institutions pilot implementation of machine-actionable DMPs at their university. We’ve seen prototypes and mockups for integrations related to resource allocation, interdepartmental communication, security policies, AI-review, and so much more. We’ve brought on Clare Dean to help us create resources and toolkits, disseminate the findings, and host a series of webinars about what we’ve learned to help others implement at their own universities. We’ll be presenting talks on the DMP Tool at IDCC25 in February, RDAP in March, and we plan to submit for other conferences throughout the year, including IDW/RDA in October, to share what we’ve learned with others. We hope to continue working with DMP-related groups in RDA to ensure our work is compatible with others in the space, and we’re following best practices for API development.
We hope you’re as excited for these projects as we are! We’re a small team but we work with many amazing partners that help us achieve ambitious goals. Keep an eye on this space for more to come.
We’re making progress on our plan to match DMPs to associated research outputs.
We’ve brought in partners from COKI who have applied machine-learning tools to match based on the content of a DMP, not just structured metadata.
We’re getting feedback from our maDMSP pilot project to learn from our first pass.
In our new rebuilt tool, we plan to have an automated system to show researchers potential connected research outputs to add to the DMP record.
Connecting Related Works
Have you ever looked at an older Data Management Plan (DMP) and wondered where you could find resulting datasets it mentioned would be shared? Even if you don’t sit around reading DMPs for fun like we do, you can imagine how useful it would be to have a way to track and find published research outputs from from a grant proposal or research protocol.
To make this kind of discovery easier, we aim to make DMPs more than just static documents used only in grant submissions. By using the rich information already available in a DMP, we can create dynamic connections between the planned research outputs — such as datasets, software, preprints, and traditional papers — and their eventual appearance in repositories, citation indexes, or other platforms.
Rather than linking each output manually to their DMP, we’re using the new structure of our machine actionable data management and sharing plans (maDMSPs) from our rebuild to help automate these connections as much as possible. By scanning relevant repositories and matching the metadata to information in published DMPs, we can find potential connections that researchers or librarians just have to confirm or reject, without adding the information themselves. This keeps them in control and helps ensure connections are accurate, while reducing the burden of how much information they have to enter.
Image from an early version of this in the DMP Tool showing a list of citations for potential marches with buttons to Review and a status column showing them as Approved or Pending
This helps support the FAIR principles, particularly making the data outputs more findable, and helps transform DMPs into useful, living documents that provide a map to a research project’s outputs throughout the research lifecycle.
Funders, librarians, grant administrators, research offices, and other researchers will all benefit from a tracking system like this being available. And thanks to a grant from the Chan Zuckerberg Initiative (CZI), we were able to start developing and improving the technology to start searching across the scholarly ecosystem and matching to DMPs.
The Matching Process
We started with DataCite, matching based on titles, contributors (names and ORCIDs), affiliations, and funders (names, RORs and Crossref funder ids). Turns out, when you have a lot of prolific researchers, they can have many different projects going on in the same topic area, so that’s not always enough information to to find the dataset from this particular project. We don’t want to just find any datasets or papers that any monkey-researcher has published about monkeys, we want to find the ones that are from this particular grant about monkey behavior.
To help expand the datasets and other outputs we could find, we partnered with the Curtin Open Knowledge Initiative (COKI) to ingest information from OpenAlex and Crossref, and we’re working on including additional sources like the Data Citation Corpus from Make Data Count. COKI’s developers are also applying machine-learning, using embeddings generated by large language models and vector similarity search to compare the text from the title and abstract of a DMP to those descriptive fields within the datasets, rather than just the metadata for authors and funders. That will help us match if, say, the DMP mentions “monkeys” but the dataset uses the work “simiiformes.”
To confirm the matches, we used pilot maDMSPs from institutions that are part of our projects with our partners at the Association of Research Libraries, funded by the Institute of Museum and Library Sciences and the National Science Foundation. This process recently yielded a list of 1,525 potential matches to registered DMPs from the pilot institutions. We asked members of the pilot cohort to evaluate the accuracy of these matches, providing us with a set of training data we can use to test and refine our models. For now we provided the potential matches in a Google Sheet, but in the future with our rebuild we plan to integrate this flow directly in the tool.
Screenshot from one university’s Google Sheet for matching DMP-IDs to research output DOIs, showing some marked as Yes, No, and Unsure for if its a match
Initial Findings
It will take some time for the partners to finish judging all the matches, but so far about half of the potential related works were confirmed as related to the DMP. This means we’ve got a good start and can use the ones that didn’t match to train our model better. We’ll use those false positives, as well as false negatives gathered from partners, to refine our matching and get better over time. Since we’re asking the researchers to approve the matches, we’re not too worried about false matches, but we do want to find as many as possible.
This process is still early, but here are some of our initial learnings:
Data normalization is an important and often challenging step within the matching process. In order to match DMPs to different datasets, we need to make sure that each field is represented consistently. Even a structured identifier like a DOI can be represented with many different formats across and within the sources we’re searching. For example, sometimes they might include the full URL, sometimes just the identifier, and some are cut off and therefore have an incorrect ID that needs to be corrected in order to resolve. That’s just one small example, but there are many more that make the cleanup difficult, including normalization of affiliation, funder, grant and researcher identifiers across and within the datasets. Without the ability to properly parse the information, even a seemingly comprehensive source of data may not be useful for finding matches.
Articles are still much easier to find and match than datasets. This is not surprising, given the more robust metadata associated with DOIs for articles that make them easier to find. Data deposited into repositories often does not have the same level of metadata available to match, if a DOI and associated metadata are even available at all. We’re hoping we can use those articles, which may mention datasets, to find more matches in our next pass.
There is not likely to be a magic solution that gets us to completely automate the process of matching a research output to a DMP without changes in our scholarly infrastructure. Researchers conduct a lot of research in the same topic area, so it’s difficult to know for sure if a paper or dataset came from a DMP, unless they specifically include these references. There are ways to improve this, such as using DOIs and their metadata to create bi-directional links between funding and their outputs (as opposed to one-directional use of grant identifiers), including in data repositories. DataCite and Crossref are both actively working to build a community around these practices, but many challenges still remain. Because of this, we plan to have the researcher confirm matches before they are added to a record, rather than attempt to add them automatically.
Next Steps
We’re continuing to spend most of our development work on our site rebuild, which is why we’re grateful for our funding from CZI and our partnership with COKI to improve our matching. Our next step is including information from the Make Data Count Data Citation Corpus, as well as following up on the initial matches once pilot partners finish their determinations.
We hope to have this Related Works flow added to our rebuilt dmptool.org website in the future. The mockup is below (where we show researchers that we have found potential related works on a DMP, and would then ask them to confirm if it’s related so it can be added to the metadata for the DMP-ID and become part of the scholarly record). We’ll want to balance confidence and breadth, finding an appropriate sensitivity so that we don’t miss potential matches but also don’t spam people with too many unrelated works.
Mockup of a project block in the new DMP Tool which a red pip and test saying “Related works found”
If you have feedback on how you would want this process to work, feel free to reach out!
As mentioned in our last blog post, the team behind the DMP Tool has been working on a rebuild of the application to improve usability, add new features, and provide additional machine-actionable features. To provide all of this advanced functionality, we needed to do a pretty big overhaul of the technology behind the DMP Tool, and it was a good time to give the design a more modern upgrade as well, adding new functionality while hopefully making existing features easier to use.
How we made the first drafts and tested them
Over the past few months, we’ve worked closely with a team of designers to create interactive wireframes—prototype mockups that allow us to test potential updates to the user interface without fully developing them. These wireframes are crucial for gathering feedback from real users early, ensuring that our vision for a better tool meets their expectations. While a lot of thought and planning went into these initial designs, we wanted to make sure people were finding the new site as easy and intuitive as possible, while still offering new, more intricate features.
To do this, we recruited three groups of people, 12 total, who work on different parts of the tool to test out these designs:
5 researchers, who would be writing DMPs in the tool
4 organizational administrators, who would be adding guidance to template in the tool
3 members of the editorial board or funder representatives, who would be creating templates in the tool
We recruited volunteers from the pilot project members, from our editorial board, from social media, and from asking those we recruited to share the invitation with others. We conducted virtual interviews with each person individually, where we let them explore the wireframe for their section, gave them tasks to complete (e.g., “Share this DMP with someone else”), and asked questions about their experience. For the most part we let people walk through the wireframes as if they were using it for real, thinking out loud about what they were experiencing and expecting.
What we found from testing
It was illuminating for the team to see live user reactions from these sessions, and watch them use this new tool we’re excited to continue work on.
We loved to hear users say how excited they were for a particular new feature or how much they liked a new page style. At times it could be disheartening, watching a user not find something that we thought was accessible, but those findings are even more important because it means we have an area to improve. We made a report about the findings after each group of users and worked with the designers on how to address the pain points. Sometimes the solution was straightforward, while other times we wrestled with different options for weeks after testing.
Overall, we found that people liked the new designs and layout and could get through most tasks successfully. They appreciated the more modern layout and additional options. But there were many areas that the testers identified as confusing or unclear. There are specific examples, with before-and-after screenshots, in the Appendix. Some of the top changes made revolved around the following areas:
Decreasing some text in areas that felt overwhelming, moving less important information to other pages or collapsed by default
Adding some text to areas that were particularly unclear, such as what selecting “Tags” for a template question would do
Connecting pages if people consistently went somewhere else, such as adding a link to sharing settings on the Project Members page since that’s where people looked for it first
Moving some features to not show until they’re needed, such as having Visibility settings as an option in the publishing step and not the drafting step
Clarifying language throughout when things were unclear, such as distinguishing whether “Question Requirements” was about what the plan writer was required to write when creating their DMP or whether that was about the template creator marking whether a question is required or had display logic
Having additional preview options when creating a template or adding guidance to understand what a question or section would look like to a user writing a DMP
Making certain buttons more prominent if they were the primary action on a page, like downloading a completed DMP that originally was hard to find
Even though the main structure worked well for people, these small issues would have added up to a lot more confusion and obstacles for users if we hadn’t identified them before releasing.
Wrapping up and moving forward
The whole team learned a ton from these sessions, and we’re grateful to all the participants who signed up and gave their time to help us improve the tool. This sort of testing was invaluable to find areas to improve – we made dozens, if not hundreds, of small and large changes to the wireframes based on this testing, and we hope it’s now much better than it was originally. We’re still working on updates as we build our designs for more areas of the site, but feel better now about our core functionality.
If you’d like to be invited to participate in surveys, interviews, or other feedback opportunities like this for the DMP Tool, please fill out this brief form here: Feedback Panel Sign-Up. For anyone that signed up but wasn’t selected for this round, we may reach out in the future!
We loved seeing how excited people are about this update, and we can’t wait to share more. The most common question we get is – when is it releasing! That’s going to be quite some time, and we don’t have more to share yet, as we’re still too early in the development process. But stay tuned here for more updates as we do!
We want to thank Chan Zuckerberg Initiative (CZI) for their generous support for rearchitecting our platform. We wouldn’t be able to make all of these helpful updates along with our back-end transformations without it.
Appendix: Specific Examples
Important note: The “updated wireframes” shown here are not final designs. We have not yet completed a design pass for things like fonts, colors, spacing, and accessibility; this is just a quick functionality prototype so we could get early feedback. Even the functionality shown here may change as we develop based on additional feedback, technical challenges, or other issues identified. Additionally, these wireframes are mockups and do not have real data in them, so there may be inconsistent or incorrect info in affiliations, templates, etc; we were focused on the overall user interface in testing, not specific content.
Sharing settings
For those who want some more details and specific examples, here are a few of the top areas of confusion we found:
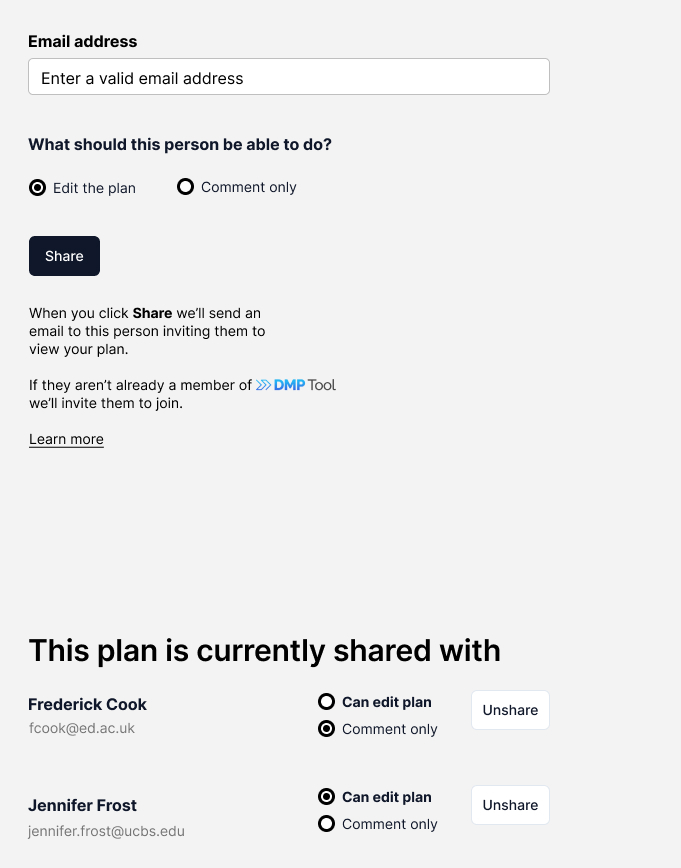
There was sometimes confusion in how to share a plan with others, and what the distinction is between a Project collaborator (e.g., another researcher on the grant who may not be involved in the DMP) and a DMP collaborator (e.g., a peer who is giving feedback on writing the DMP but not on the project). The current live tool has both “Project Contributors” and “DMP Collaborators” on the same page which we thought contributed to this confusion, so we wanted to separate those who can edit the DMP into a separate Sharing section. However, testers had a hard time finding these sharing settings, and often went to the Collaborators page to grant DMP access. So, we added a link to these settings where people were looking (the new section in the green box), and added more detail to the sharing page about whether they were invited or had access due to being a collaborator, changed some language within this like “Collaborator” to “Project Member,” with the option to change access.
Current tool:
On the current tool, these two types of collaborators are on one page.
Initial wireframes:
The Collaborators page in the initial wireframes, which was part of the overall project details and was not related to sharing access to the DMP itself.A separate Sharing page on the plan itself had sharing settings, and was completely distinct from Collaborators.
Updated wireframes:
This page was renamed to Project Members for clarity, with a link to the page for sharing access to the DMP since so many people looked for it here.This page was updated to give more information and control on invitations, and to make clear if people were added on because of an invite or because they were a project collaborator.
Card layout
Many parts of the tool used a new, more modern card format for displaying lists of items to choose from. This allowed us to show more information than in a list, and adapt to smaller screens. However, we saw in some areas that people had trouble scanning these cards to find what they were looking for, like a plan or template, when they expected to search in alphabetical order.
For example, picking a template in the first draft used a boxier card format. People found it harder to find the template they were looking for, since they wanted to quickly scan the titles vertically. So we changed it to a different format that should be easier to scan, even if it doesn’t show as many on one page. Note we also now have the option to pick a template other than from your funder, a common request in the current tool.
Current tool:
Currently, selecting your funder brings up a list of templates with no other information, and you can’t select a different template.
Initial wireframe:
This format allows more information if we want to add details that might help people pick the right template.
Updated wireframe:
This update still allows us to show more information, but the vertical layout means a person’s eyes can move in the same spot down the list to scan titles more easily if they know what they want.
Flow through the tool
People appreciated that they could move around more freely in the new design, as compared to the more linear format of the current tool. However, that also occasionally made people feel “lost” as to where they were in the process of writing a DMP. Especially as there is now a “Project” level above each plan to help support when people have multiple DMPs for the same research project. So we added more guidance, breadcrumbs, and navigation while still allowing the freedom of movement throughout the process.
For example, while writing a plan, users will now be able to see the other sections available and understand where they are in the Project tree. We also reduced some of the text on screen due to people feeling overwhelmed with information, putting some best practices behind links that people can visit if they wish to, and moved the Sample Answer people were most interested in to above the text box for better visibility.
Current tool:
The current tool has more distinct phases from writing a plan to publishing. In this view, a person is answering a single question and then would move on to the next.
Initial wireframe:
In our first draft, people clicked into each question rather than having all one one expandable page. But people weren’t always sure where they were in the process or how to get back.
Updated wireframe:
We added the navigation seen on the left and top here to allow people to see what else is in the plan and more easily get to other sections or the Project. We are also still working on how to reduce how much text is on the screen at once, for example by minimizing the guidance, but this is not final. We also moved the sample text above the question and removed the answer library for now.
Layout changes
In addition, there were tons of small changes throughout, changing layouts, wordings, and ordering of options in response to areas of confusion. Some places we scaled back a bit of functionality since the number of new options were overwhelming, while other places we added a bit more that people needed.
In the first draft of the wireframes, the visibility settings of the plan were on the main overview page of the plan. This was concerning to users since they were still drafting at this stage, and even if they may want it public once they published it, the setting in this location made it seem like it was public now. Instead we added a status and setting on the overview page, but the visibility setting does come up until a person gets to the Publish step, somewhat like the current tool that has those options later than in the plan writing stage.
Current tool:
Currently, setting visibility is later in the “Finalize” stage.
Initial wireframe:
In the first draft, this visibility settings were on the main plan page, which made people think it was public already as opposed to that it would be public once published.
Updated wireframe:
The updated main page, with many changes based on feedback, including visibility as a status on the right, which isn’t set until it is published, and more control over changing project details per plan.Now, visibility is set only once a person goes to publish their DMP.
We made similar change to creating a template, moving the visibility settings to be selected in the publishing stage instead of being in a Template Options menu people didn’t always see right away. They expected to set that visibility at the time they published it, so that’s where we moved that option to be, consistent with how the plan creation flow works.
Over the past 13 years, the DMP Tool has grown from a grassroots tool beginning at 8 institutions to one that serves thousands of universities across multiple continents. We’ve had a few big milestones in that time, such as adding the ability to register a DMP-ID and publish a DMP publicly, and creating the admin interface to allow universities to provide custom guidance on templates. The tool started in response to new requirements from U.S. funders for data management plans (DMPs; also known as data management and sharing plans–DMSPs), and our growth follows the research and library communities’ needs in this area.
Adding Machine-Actionable Functionality
Now, it’s time for our next big milestone in the DMP Tool: fully machine-actionable data management and sharing plans (maDMSPs). In 2022, the U.S. CHIPS and Science Act was signed into law, requiring DMPs submitted to the National Science Foundation (NSF) to be “machine-readable.” Machine-readable, or actionable, means that information is structured in a way that enables automatic connections and transformations without the need for manual intervention.
Excerpt from the CHIPS & Science Act, referring to NSF-funded research
On the current DMP Tool, some parts of the DMP have been made machine-actionable already, such as the DMP-ID and metadata. When you go to a registered DMP’s landing page, like this public plan for example, you see structure information like title and contributors pulled from a database. Other systems can work with that information through our public API, allowing for integrations with various research applications.
Now, we want to make all parts of the DMP – such as the narrative responses to the questions describing the plan – machine-actionable, and open up more tooling to work with structured maDMSPs, as was outlined in a Dear Colleague letter in 2019.
There are many benefits to maDMSPs, such as:
Having persistent identifiers that allow tracking of data publications and connections to other PIDs, like ORCIDs and ROR and DOIs
Creating opportunities for sharing information about DMPs between different campus units
Allowing integrations with research systems, like electronic lab notebooks, that can help researchers use DMPs in existing workflows
Establishing links to research outputs, like published datasets, that came from a DMP, to help link work and track compliance with the statements in a DMP
Rebuilding the DMP Tool
To implement these major changes, we realized a significant overhaul of the current DMP Tool was needed to accommodate these new features and underlying structural changes. For years, the DMP Tool rebuild has been a regular discussion point; we’ve long recognized its areas for improvement and regularly fielded requests for specific features. However, our team of two had limited ability to implement many of our, and the community’s, grand ideas.
Fortunately, we were able to obtain funding from an NSF EAGER grant that allowed us to explore a rebuild of the application, which would allow us to develop these features of the new tool and bring about these needed changes.
Our official rebuild work kicked off in April 2024 with a week-long workshop with our new team of consultants led by Paula Reeves from Reeves Branding and Zach Antony from Cazinc Digital. During that week, we dove into every aspect of the current application, mapping out existing features and brainstorming how to incorporate new ones. This included the machine-actionable data and formatting required for interoperability and the structured metadata needed to fuel the creation of machine-actionable data management plans. We reviewed the existing architecture, explored user personas, and redesigned workflows to facilitate project-centric planning. We also focused on building and customizing templates, adding guidance tools, and ensuring accessibility as we outlined development timelines and workflows for future phases.
The seven team members at the rebuild kickoff meeting
We’re excited to also get in a few top feature requests as well as maDMSP functionality, though we will be rolling them out in stages and cannot get to everything. Some of the areas we have currently prioritized include:
Additional API functionality, such as the ability with unpublished or in-progress DMPs
Ability to upload and register existing DMPs
Improved account management, such as being able to add secondary emails
Increased flexibility in creating templates, such as additional question types and streamlined ability to copy templates
Finding and connecting DMPs to published research outputs like datasets
Improved notification, comment, and feedback systems
Since the kick-off, the designers have been developing wireframes for the new tool, while we’ve added some new machine actionable elements to the current DMP Tool for testing. We’ve been working with the Association of Research Libraries (ARL) on a pilot project with 10 institutions, funded by the Institute for Museum and Library Sciences, gathering feedback from their use of the tool and conducting interviews about their efforts developing local integrations. Our first visit was to Northwestern University, which can read more about on ARL’s blog, with more coming soon.
What’s next
To stay focused on delivering this work, and due to the site’s technological constraints, we will be limiting updates to the current application. We’ll prioritize resolving critical issues while taking feature requests as requests for the new site.
We can’t wait to share more information over time about this project as it develops. While it’s too early to announce a release date, we’re hopeful it will be sometime before the end of next year. We recently wrapped up user testing on the wireframes, and will have a blog post coming soon about what we found. We’ll also be sharing information at upcoming conferences, such as a talk at IDCC25 called “Piloting maDMSPs for Streamlined Research Data Management Workflows.” Keep an eye on this space, and sign up for our newsletter, to hear occasional updates about this work!
We want to also thank Chan Zuckerberg Initiative (CZI) for their generous support for rearchitecting our platform. The back-end transformations and refactoring activities were funded through their generous support.
I’m thrilled to introduce Becky Grady, CDL’s new Senior Product Manager for Data Management Planning. Becky will oversee our work on the DMP Tool and machine-actionable DMP projects. She brings a wealth of experience in technical product management to our team, and we’re excited to have her on board! As for me, I’ve transitioned to a new role as the Associate Director of the UC3 department. While I’ll continue working to support the development of the DMP Tool and new maDMP workflows, Becky will now be the lead contact for all DMP-related projects. – Maria Praetzellis
Hello everyone! My name is Becky Grady, and I’m thrilled to be joining UC3 to work on Data Management planning.
For the past few years I’ve worked as both a UX researcher and a product manager in the tech industry, working on gaming platforms, account systems, and internal tools. Before that, I received my PhD in Psychological Science at UC Irvine, studying bias in false memory, fake news, and misinformation under advisors Elizabeth Lofuts and Pete Ditto.
As a former researcher, I know how important open science practices are at every stage of the process. I’ve published multiple meta-analyses and know firsthand, both as the requestor and the requestee, of the challenges in finding and sharing data and materials from long ago. I’ve also conducted many studies, from both academia and industry, about meta-science practices such as survey design and replication processes, because I know how important it is to look at how we conduct research and not just what the output is.
As a product manager, I know how important it is to provide the right tools for people to get done what they need, understanding their needs and goals to make a great experience for them. My UX research experience helps me work with users to understand their motivations, getting to their core needs to build the product that does what they need.
I can’t wait to bring my industry and academic experiences together to help in this important area and help plan, track, and preserve critical research data. Making it easy and intuitive to create and update data management plans, serving the needs of both researchers and institutions, will be core to advancing open science practices. Excited to work with all of you more! You can reach me at becky.grady@ucop.edu or connect with me on LinkedIn.
The MAP Pilot project involves working with 10 institutions across the US to test connecting machine-actionable data management and sharing plans (maDMSPs) with related research outputs. Using research project metadata and persistent identifiers to query open data sources, it is somewhat easy to find research articles produced by a particular project, but not the datasets, software and other artifacts that are described in a DMSP. We are investigating ways to improve their findability using automation including machine learning/AI.
When maDMSPs are created in the DMP Tool, users can enter useful project metadata to enable queries with other systems. This includes ORCIDs for contributors, funding opportunity identifiers, RORs for affiliations and funders, anticipated project start and end dates, and the planned data repository for storage. The DMP Tool then assigns a DMP ID to the DMSP.
DMSPs are often created years before the research outputs. The DMSPs in the DMP Tool with good metadata are only 2-3 years old, and their DMSP outputs have not yet been published. Therefore, the institutions contributing to our pilot have been asked to find older, funded research projects and their outputs to use as test cases. Using a new feature to upload an existing DMSP, they will enter basic information about the project (i.e., title, PI, grant identifiers) for research funded by 4 major US agencies (NSF, NIH, DOE, and NASA) and for which we have the most developed API integrations. As potential DMSP outputs are identified, the pilot teams will verify their relation to the research.
Identifying related DMSP outputs within the DMP Tool will give data librarians and research/grant management offices insight into the outputs of research projects, academic departments, and the institution. Users can generate reports for compliance checks (was the data shared according to the funder’s policy), grant reporting, and research management activities. This collaborative effort is being further developed with the Centre for Open Knowledge Infrastructure (COKI) and is funded by the Chan Zuckerberg Initiative (CZI), which supports technical work to connect plans to outputs.
With sufficient metadata, how do we find related DMSP outputs? We start by exploring open data sources like Crossref, DataCite, and COKI. For example, we explore DataCite’s GraphQL API to extract DataCite metadata and compare it with DMP Tool projects. We use an algorithm to compare and score each field in the records. Each data source structures its metadata differently, though, so we must transform that metadata into a standardized format. We then weigh or score the confidence level of any matches found. A high confidence level is when grant IDs match, but this is rare currently. Confidence levels improve with additional identifiers like ORCIDs, RORs, and repository IDs.
Some development challenges discussed at the workshop include:
US funding agencies lack a standard way of sharing metadata via their APIs and rarely include Grant IDs. Grant IDs are important but not reliable yet for identification purposes.
Research/DMSP outputs associated with older projects frequently lack identifiers such as ROR and ORCIDs in their metadata record.
How can we find datasets and software related to published research articles in systems like COKI? Can we use an article’s references to find these artifacts? What other hooks will allow us to identify these related outputs, and how could improved metadata and the usage of identifiers help facilitate making these connections?
We are exploring adding more data aggregators to combine findings and create a clearer picture of a research project and its outputs. We will also explore methods to identify related works from research article reference sections, like dataset or software references. We are experimenting with ML/AI techniques to determine if a research output might be related to a DMSP.
Findings from the MAP Pilot will be published as reports and best practices for implementing maDMSP workflows at research institutions after the project ends in 2025. If interested in collaborating on this important developmental work, please contact muhlmansiek [at] arl [dot] org for more information.
By Mary O’Brien Uhlmansiek, Project Director, The Association of Research Libraries (ARL)
This February, I joined the MAP Pilot team as Project Director, serving in a joint position with The Association of Research Libraries (ARL) and the California Digital Library (CDL). In this role, I will support ten research libraries in our pilot project, exploring ways to advance institutional coordination around machine-actionable data management and sharing plans (maDMSPs). The project will compile resources for research workflow improvements utilizing maDMSPs, such as for tracking compliance with funder data-sharing requirements or to initiate internal research infrastructure requests upon grant award, for example. Our pilot partners will also help drive improvements in the DMP Tool itself, providing valuable software testing and feedback as new interoperability features are developed, and using real-world examples to ensure the application will meet the needs of researchers and stakeholders alike.
Through my experiences serving as a data and repository manager for sensitive health-related information, in managing research software adoption and implementation at a large medical university, and as a facilitator for the adoption of outputs and recommendations at the Research Data Alliance, I can see the potential for the DMP Tool to provide critical research infrastructure for researchers and administrators alike as they navigate new data-sharing requirements from funders. I am excited to work with the project PIs, Cynthia Hudson Vitale and Maria Praetzellis, and the many other dedicated professionals from research library organizations in the open science movement. Projects such as the MAP Pilot are building blocks for the transition to more open science, and I look forward to the dissemination of the teams’ outputs to aid research institutions in adopting and continuing this important work.
We are excited to share the latest enhancements in the DMP Tool with the 5.0 release. This update marks a shift in our technology, featuring substantial back-end advancements that set the stage for a more robust, efficient, and scalable future.
Infrastructure Improvements
At the core of these updates is an overhaul of our infrastructure. The DMPTool’s back-end, built on legacy Rails code, is evolving. We’re transitioning towards a more modern architecture, separating the front-end and back-end operations. This shift involves transforming existing code into API endpoints and developing a React-based front-end. These changes will allow the DMP Tool to effectively generate the structured data required to realize the potential of machine-actionable plans.
A New Look and Feel
The first thing you’ll notice is an updated DMP Tool homepage. This redesign aims to streamline how users and prospective partners access information about the tool. Recognizing the frequent inquiries we receive about joining the DMP Tool, we’ve focused on making key information about the application more accessible and straightforward.
Versioning of Registered DMPs
Plan versioning is a key feature for machine-actionable DMPs and one we have received many requests for. Rather than static, quickly outdated documents, effective DMPs track progress by logging critical events from planning to preservation. Regularly revisiting and updating DMPs as research unfolds creates dynamic records that monitor ongoing activities.
As a first step to exposing updates to DMPs, this release also includes the introduction of versioning for plans with DMP-IDs. This means a new version is created whenever a registered DMP is updated. Changes made within the same hour are combined into a single version. This feature provides a clear history of updates and ensures that you can easily track and reference different iterations of a DMP.
We welcome your input on these latest updates. Please reach out with any comments, questions, or feedback about these changes or the DMP Tool in general.
The Association of Research Libraries (ARL) and the California Digital Library (CDL) have selected five institutional teams to pilot the integration or creation of prototypes and possible workflows for machine-actionable data management and sharing plans (maDMSPs). The pilot project will run January–December 2024. This project is funded by an Institute of Museum and Library Services (IMLS) National Leadership Grant. Additional information about the project is on our project webpage.
Machine-actionable data management and sharing plans are structured, machine-readable documents that allow for dynamic reporting on the intentions and outcomes of a research project, enabling streamlined information exchange across relevant parties and systems. These plans go beyond traditional static document-based DMSPs, and contain an inventory of key metadata about a project and its outputs (not just datasets), with a change history that stakeholders can query for information over the lifetime of the research. Implementing maDMSPs can be a key piece of establishing interconnected, automated systems for research data management and compliance.
The maDMSPs pilot institutions will help shape the development of maDMSPs and gain valuable early experience with new approaches to enable more automated and connected research data management. The institutions are:
Arizona State University
Northwestern University Feinberg School of Medicine
Pennsylvania State University
University of California, Riverside
University of Colorado, Boulder
An additional five institutions have been selected for the maDMSP extended cohort that will engage closely with the pilot cohort.
The Association of Research Libraries (ARL) and the California Digital Library (CDL) are seeking four institutional teams to pilot the integration or creation of prototypes and possible workflows for machine-actionable data management and sharing plans (maDMSPs). The pilot project will run January–December 2024. This project is funded by an Institute of Museum and Library Services (IMLS) National Leadership Grant. Additional information about the project is on our project webpage.
Interested organizations should submit their expression of interest here.
Machine-actionable data management and sharing plans are structured, machine-readable documents that allow for dynamic reporting on the intentions and outcomes of a research project, enabling streamlined information exchange across relevant parties and systems. These plans go beyond traditional static document-based DMSPs, and contain an inventory of key metadata about a project and its outputs (not just datasets), with a change history that stakeholders can query for information over the lifetime of the research. Implementing maDMSPs can be a key piece of establishing interconnected, automated systems for research data management and compliance.
This pilot provides an exciting opportunity for selected institutions to help shape the development of maDMSPs and gain valuable early experience with new approaches to enable more automated and connected research data management.
By agreeing to be part of this pilot program, institutions will:
Define a set of success measures for institutional pilot projects of maDMSPs at their organization.
Gather a sample set of data management plans from funded research projects to use as test cases for connecting plans with associated datasets and other research outputs.
Provide engaged feedback on the maDMSP features and uses at their organization.
Conduct ongoing work to meet the locally defined success measures.
Attend and actively participate in project meetings every other month.
Participate in project communication, outreach, and engagement (such as conference panels, webinars, reports and articles, etc.).
Coordinate and manage one program team site visit.
Pilot projects should include a team of three to five people representing institutional stakeholders who will work together to test or prototype an institutional solution to support public access to research data leveraging the maDMSP. Teams may include representatives from the offices of several institutional stakeholders, such as the research office, library, information technology, institutional review board (IRB), high-performance computing units, and/or faculty.
Examples of possible pilot projects include, but are not limited to:
Modeling notification workflows that could be automated through maDMSPs to alert stakeholders to key events over the data life cycle. Example use cases include alerts around sensitive data, managing big data, enabling data transfer, and linking datasets to published outputs.
Building prototype integrations connecting maDMSPs with existing research information management systems (RIMS) or researcher profile systems. For example, automatically updating and exchanging key metadata between maDMSPs and other research systems.
Engaging academic or administrative departments to test the utility of maDMPs for their research workflows and data management needs. Departmental testing would provide feedback to inform the optimization of maDMSP systems.
Demonstrating and improving communication workflows between key campus units involved in research data management using maDMSPs as a connecting platform. Example stakeholders include the library, research office, IT/security, IRB, research computing, and high-performance computing units.
Pilot institutions will:
Gain early access to new maDMSP features and functionality.
Influence technical development and workflow processes of the maDMSP platform.
Be reimbursed for up to $6,000 per institution to attend conferences or workshops to communicate pilot project goals or outcomes.
The ARL/CDL project team will produce all required reporting to IMLS; there are no federal grant reporting requirements for pilot partners.
We are seeking a range of institutions that are diverse in size, research activity, and level of development of services and infrastructure for research data management and sharing. Even if your institution has just begun planning for research data management and sharing, we invite you to apply.
Applications will remain open until Friday, November 10, 2023, and we anticipate notifying applicants by the end of November.